




Elasticsearch+应用架构设计
本文最后更新于 2025-07-04,文章超过7天没更新,应该是已完结了~
在 Elasticsearch 中,索引 就是你存储文档数据的地方,类似于数据库中的 "表"。索引包含一个或多个 文档,每个文档由多个 字段 组成。
基本概念
索引(Index):相当于数据库中的一个表,用来存储一类数据。
文档(Document):相当于数据库中的一行数据,每个文档是一个 JSON 格式的对象,包含了一个数据项的所有字段。
字段(Field):相当于数据库表中的一列,每个字段存储一个数据项的具体值。
映射(Mapping) 就是定义文档结构的方式,类似于数据库中表的定义。
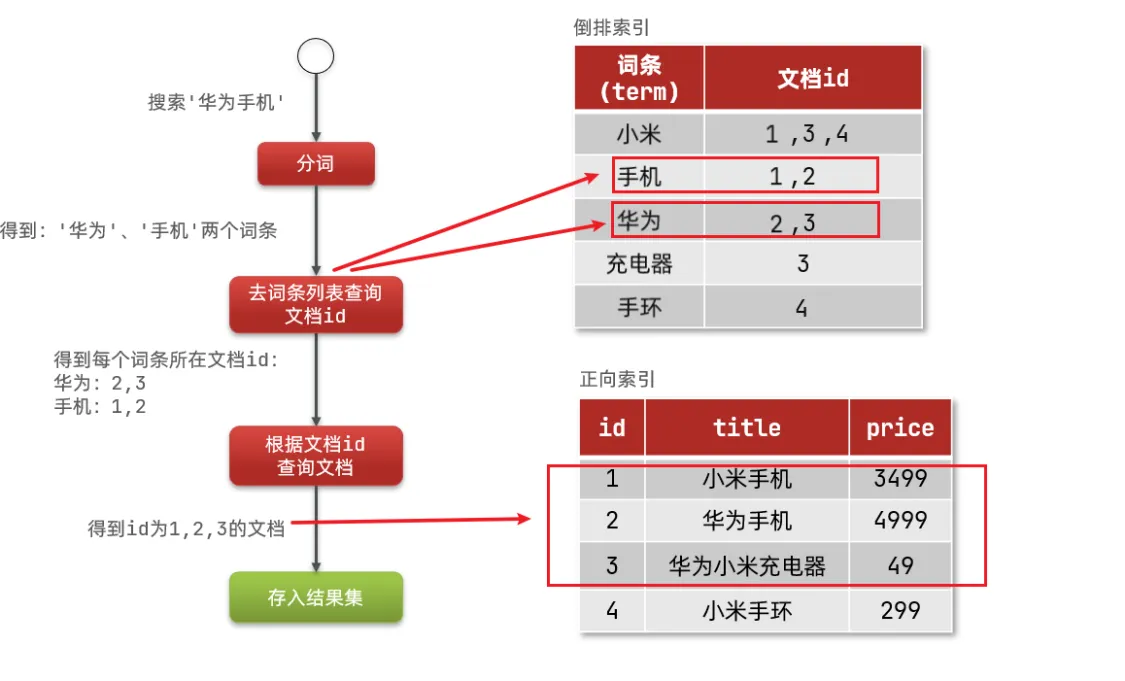
正向和倒排对比
概念区别:
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
安装es、kibana、分词器
分词器的作用是什么?
创建倒排索引时对文档分词
用户搜索时,对输入的内容分词
IK分词器有几种模式?
ik_smart:智能切分,粗粒度
ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
在词典中添加拓展词条或者停用词条
下载安装
Elasticsearch7.17.7
拉取镜像
docker pull elasticsearch:7.17.7
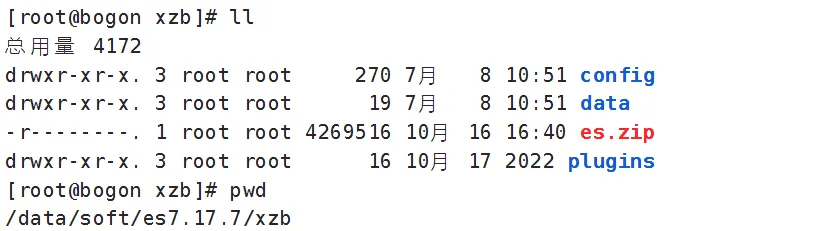
创建文件夹:
mkdir -p /data/soft/es7.17.7/xzb
在/data/soft/es7.17.7/xzb下创建data目录并且修改权限为777
mkdir data
chmod 777 data将课程资料下的"ES安装"目录中的 es.zip上传到/data/soft/es7.17.7/xzb下,并进行解压
unzip es.zip解压成功如下图:
创建容器
docker run -d \
--name elasticsearch7.17.7 \
--restart always \
-p 9200:9200 \
-p 9300:9300 \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-v /data/soft/es7.17.7/xzb/data:/usr/share/elasticsearch/data \
-v /data/soft/es7.17.7/xzb/plugins:/usr/share/elasticsearch/plugins \
-v /data/soft/es7.17.7/xzb/config:/usr/share/elasticsearch/config \
elasticsearch:7.17.7访问http://192.168.101.68:9200/,如下图说明启动成功:
4.3.3 扩展词词典
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“奥力给”,“白嫖” 等。
所以我们的词汇也需要不断的更新,IK分词器提供了扩展词汇的功能。
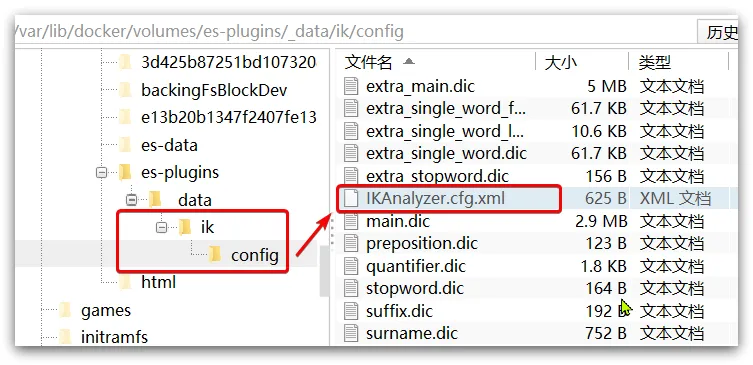
1)打开IK分词器config目录:
2)在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典-->
<entry key="ext_dict">ext.dic</entry>
</properties>3)新建一个 ext.dic,可以参考config目录下一个配置文件进行修改
白嫖
奥力给4)重启elasticsearch
docker restart es
# 查看 日志
docker logs -f elasticsearch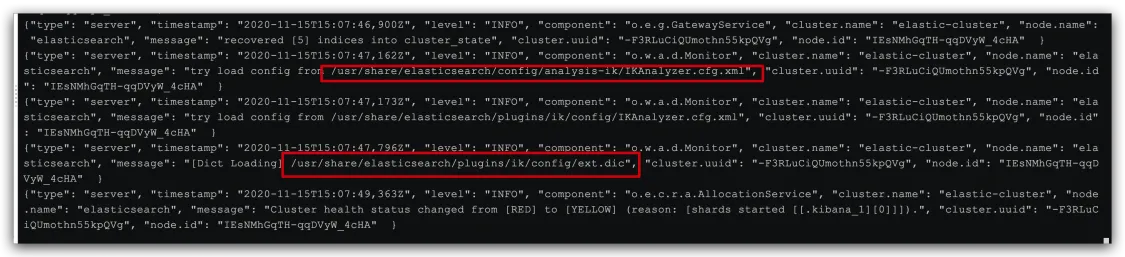
日志中已经成功加载ext.dic配置文件
5)测试效果:
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "传智播客Java就业超过90%,奥力给!"
}注意当前文件的编码必须是 UTF-8 格式,严禁使用Windows记事本编辑
4.3.4 停用词词典
在互联网项目中,在网络间传输的速度很快,所以很多语言是不允许在网络上传递的,如:关于宗教、政治等敏感词语,那么我们在搜索时也应该忽略当前词汇。
IK分词器也提供了强大的停用词功能,让我们在索引时就直接忽略当前的停用词汇表中的内容。
1)IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典-->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典-->
<entry key="ext_stopwords">stopword.dic</entry>
</properties>3)在 stopword.dic 添加停用词
大帅逼4)重启elasticsearch
# 重启服务
docker restart es
docker restart kibana
# 查看 日志
docker logs -f elasticsearch日志中已经成功加载stopword.dic配置文件
kibana7.17.7
拉取镜像
docker pull kibana:7.17.7
创建容器:
注意修改es的地址
docker run --name kibana7.17.7 \
-e ELASTICSEARCH_HOSTS=http://192.168.101.68:9200 \
-p 5601:5601 \
-d kibana:7.17.7下边启动容器,先保证Elasticsearch启动成功。
启动kibana容器成功,在浏览器输入地址访问:http://192.168.101.68:5601,进入DevTools,如下图:
执行:GET /_cat/indices?v 查询索引信息
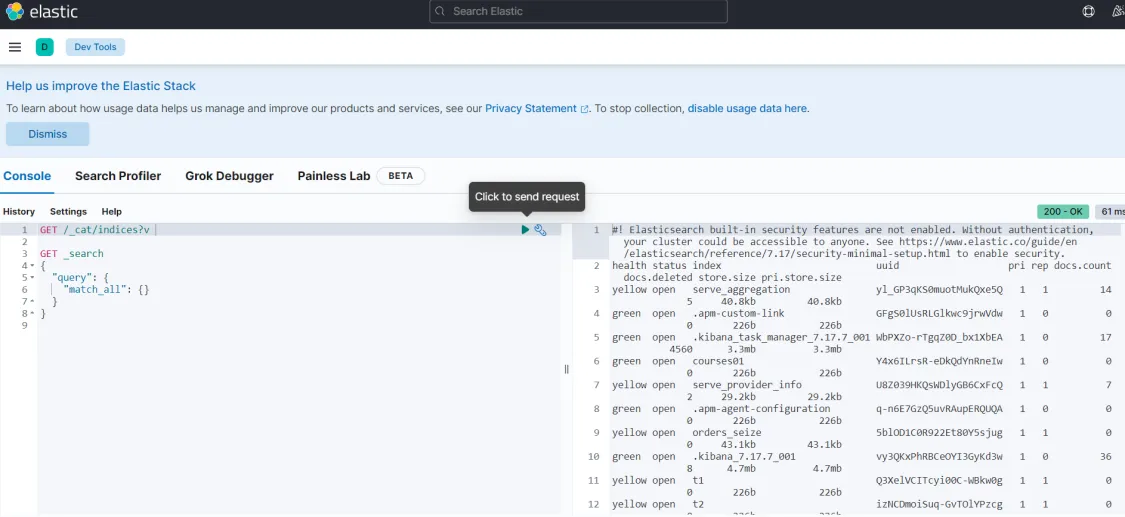
测试:
IK分词器包含两种模式:
ik_smart:最少切分ik_max_word:最细切分
在kibana的Dev tools中输入以下代码:
”analyzer“ 就是选择分词器模式
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "黑马程序员学习java太棒了"
}索引库操作
索引库就类似数据库表,mapping映射就类似表的结构。
我们要向es中存储数据,必须先创建“库”和“表”。
Mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
type:字段数据类型,常见的简单类型有:
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
keyword类型只能整体搜索,不支持搜索部分内容
数值:long、integer、short、byte、double、float、
布尔:boolean
日期:date
对象:object
index:是否创建索引,默认为true
analyzer:使用哪种分词器
properties:该字段的子字段
例如下面的json文档:
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "真相只有一个!",
"email": "zy@itcast.cn",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "柯",
"lastName": "南"
}
}对应的每个字段映射(mapping):
age:类型为 integer;参与搜索,因此需要index为true;无需分词器
weight:类型为float;参与搜索,因此需要index为true;无需分词器
isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
name:类型为object,需要定义多个子属性
name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
index: false 的设置并不意味着这些字段不会在文档中存储,而是表示它们不会参与索引(即不会被用于搜索、排序或聚合)。
在 Elasticsearch 中,即使字段不用于查询或其他操作,仍然需要保留在映射中,确保文档结构的完整性。
地理坐标字段:
在 Elasticsearch 中,地理坐标通常是通过 geo_point 类型来存储的。比如存储地理坐标的字段可能是这样的格式:
"location": {
"type": "geo_point"
}
还有一种叫geo_shape 适用于存储更复杂的地理形状,如多边形、矩形、圆形等,可以进行复杂的空间查询,比如查找某个形状内的地理点。
这样,您可以存储如 纬度, 经度 的地理坐标(例如:39.9, 116.4),并使用 Elasticsearch 提供的地理查询功能(如 geo_distance 查询、geo_bounding_box 等)来进行地理位置相关的搜索。
copy_to 组合字段:
在 Elasticsearch 中,copy_to 用于将多个字段的内容合并到一个新的字段。举个例子:
"properties": {
"title": {
"type": "text"
},
"description": {
"type": "text"
},
"combined_fields": {
"type": "text",
"copy_to": ["title", "description"]
}
}
在这个例子中,combined_fields 是一个组合字段,它将 title 和 description 字段的内容都到 combined_fields 中。这样,当用户进行查询时,可以直接查询 combined_fields,它实际上包含了 title 和 description 的内容,从而简化了查询逻辑,避免了同时查询多个字段。
通过这种方式,用户可以用一个查询关键词来查找多个字段的内容(如标题和描述),而无需分别查询每个字段。
根据MySQL数据库表结构(建表语句),去写索引库结构JSON。表和索引库一一对应
创建索引库,最关键的是mapping映射,而mapping映射要考虑的信息包括:
字段名
字段数据类型
是否参与搜索
是否需要分词
如果分词,分词器是什么?
其中:
字段名、字段数据类型,可以参考数据表结构的名称和类型
是否参与搜索要分析业务来判断,例如图片地址,就无需参与搜索
是否分词呢要看内容,内容如果是一个整体就无需分词,反之则要分词
分词器,我们可以统一使用ik_max_word
索引库的CRUD
创建索引库:PUT /索引库名
查询索引库:GET /索引库名
删除索引库:DELETE /索引库名
修改索引库(添加字段):PUT /索引库名/_mapping
创建索引库
PUT /orders_seize
{
"mappings" : {
"properties" : {
"city_code" : {
"type" : "keyword"
},
"id" : {
"type" : "long"
},
"key_words" : {
"type" : "text",
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"location" : {
"type" : "geo_point"
},
"orders_amount" : {
"type" : "float"
},
"pur_num" : {
"type" : "integer"
},
"serve_address" : {
"type" : "text",
"index" : false
},
"serve_item_id" : {
"type" : "long"
},
"serve_item_img" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256 //用来控制 如果字段值超过指定字符长度(此处为 256 字符)时,自动不索引该字段
}
}
},
"serve_item_name" : {
"type" : "text",
"index" : false
},
"serve_start_time" : {
"type" : "text",
"index" : false
},
"serve_time" : {
"type" : "integer"
},
"serve_type_id" : {
"type" : "long"
},
"serve_type_name" : {
"type" : "text",
"index" : false
},
"total_amount" : {
"type" : "double"
},
"address": {
"type": "object", // 你还可以在 object 中嵌套另一个 object
"properties": {
"city": {
"type": "text"
},
"postcode": {
"type": "keyword"
}
}
}
}
}
}analyzer: "ik_max_word":适用于 索引阶段,希望能够分出更多的细节和细粒度的词项,适合需要广泛匹配的场景。比如搜索时用户输入了部分关键词时,可以返回更多可能的匹配。search_analyzer: "ik_smart":适用于 查询阶段,希望减少分词的复杂度,只考虑主要的词项,适合精确搜索。比如对于搜索时的查询输入,仅关注主要的关键字,而忽略一些不必要的细节。
终于搞懂“ fields”有啥用了
通过使用 fields,你可以避免为同一数据定义多个字段。例如,如果你有一个 title 字段,并且需要同时处理全文搜索和精确匹配查询,如果不用 fields,你就必须为 title 创建两个不同的字段:
{
"title": {
"type": "text"
},
"title_keyword": {
"type": "keyword"
}
}这意味着你必须维护两个字段:title 和 title_keyword。这种重复不仅会增加索引大小,还会让映射变得复杂。
但如果使用 fields,就只需要一个 title 字段,通过不同的子字段来处理不同类型的查询(创建文档依旧是两个字段哦):
{
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}这样,你只需要处理一个 title 字段,它可以同时满足 全文搜索(title)和 精确匹配(title.keyword)的需求。通过 fields,你将不同的用途放在同一个字段下,而不是重复定义多个字段。
查询父字段(全文搜索):
如果你想对 title 字段进行 全文搜索,使用 标准的 title 字段 进行搜索。这里 Elasticsearch 会自动进行分词处理:
GET /your_index/_search
{
"query": {
"match": {
"title": "tokenized search"
}
}
}title字段会通过text类型进行分词,所以可以进行 全文搜索。
查询子字段(精确匹配):
如果你想对 abc 字段进行 精确匹配,你必须使用 title.abc 这个子字段。abc 字段是 keyword 类型,适用于精确查询。
GET /your_index/_search
{
"query": {
"term": {
"title.abc": "Exact Title"
}
}
}这里使用
term查询进行 精确匹配,因为title.abc是keyword类型,它没有分词处理,适用于 精确匹配 和 聚合。
总结:
减少字段重复:只需要一个字段名
title,就可以实现多个不同的查询用途(全文搜索、精确匹配、聚合等)。查询灵活:可以针对不同的查询需求选择不同的子字段进行查询,而不需要定义多个字段。
优化存储与性能:为字段提供多种存储方式,提高存储效率,避免重复存储。
简化映射结构:通过
fields,避免了字段冗余,保持了数据结构的简洁。便于扩展:后期如果需要新增查询功能,直接在
fields中添加子字段,避免修改现有的字段结构。减少应用代码复杂度:不需要在应用层处理多个字段的逻辑,查询时直接选择子字段。
创建索引- 动态模板
动态模板允许你为某一类字段定义映射规则,而不是为每个字段手动指定映射。这是在动态映射开启的情况下,自动为特定类型的字段指定映射方式的一种机制。
使用场景
当你不确定数据中是否会包含某些字段时,可以使用动态模板来为这些字段指定默认的映射方式,避免每次都手动定义映射。
示例
假设我们有一个索引,需要根据字段的名称动态地决定字段类型。比如,所有以date_开头的字段都应该被映射为date类型,所有以amount_开头的字段都应该被映射为float类型。
PUT /my_index
{
"mappings": {
"dynamic_templates": [
{
"dates_as_date": {
"match": "date_*",
"mapping": {
"type": "date"
}
}
},
{
"amounts_as_float": {
"match": "amount_*",
"mapping": {
"type": "float"
}
}
}
]
}
}解释
dynamic_templates: 这个字段包含一个或多个动态模板。match: 定义匹配字段的规则,可以使用通配符(如date_*)来匹配所有以date_开头的字段。mapping: 定义匹配到的字段应该使用的映射类型。
当你向这个索引添加文档时,任何以date_开头的字段将会自动被识别为date类型,所有以amount_开头的字段会被识别为float类型。
创建索引- 索引模板
索引模板是用来为一组索引定义共享设置、映射和别名的方式。当创建新索引时,符合模板模式的索引会自动继承这些设置和映射。
使用场景
当你创建了多个结构相似的索引时,索引模板非常有用。比如,每个月创建的日志索引或每个部门的指标数据索引,都可以使用相同的映射和设置。
示例
假设我们想为所有名称以logs-*开头的索引设置共享的映射和设置,可以使用索引模板。
PUT /_template/logs_template
{
"index_patterns": ["logs-*"],
"mappings": {
"properties": {
"timestamp": {
"type": "date"
},
"message": {
"type": "text"
},
"level": {
"type": "keyword"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}解释
index_patterns: 定义模板适用的索引模式。这里的logs-*表示所有以logs-开头的索引都会使用这个模板。mappings: 定义该模板下的索引映射,比如timestamp字段是date类型,message字段是text类型。settings: 定义该模板下的索引设置,比如设置number_of_shards和number_of_replicas。
通过这个索引模板,任何创建的名称为logs-2025-02-*或logs-2025-03-*的索引都会自动继承这个模板的映射和设置。
修改索引库(添加字段)
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
语法说明:
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}文档操作
文档操作有哪些?
创建文档:POST /{索引库名}/_doc/文档id
查询文档:GET /{索引库名}/_doc/文档id
删除文档:DELETE /{索引库名}/_doc/文档id
修改文档:
全量修改:PUT /{索引库名}/_doc/文档id
增量修改:POST /{索引库名}/_update/文档id { "doc": {字段}}
1. 文档的CRUD
1.1 新增文档
语法:
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
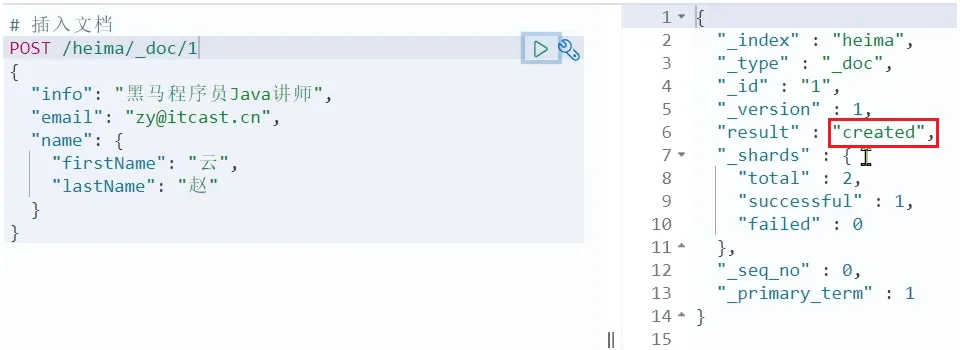
}示例:
POST /heima/_doc/1
{
"info": "真相只有一个!",
"email": "zy@itcast.cn",
"name": {
"firstName": "柯",
"lastName": "南"
}
}响应:
1.2 查询文档(重点)
1. 基本的匹配(Query)查询
POST /bookdb_index/book/_search
{
"query": {
"match" : {
"title" : "in action"
}
},
"size": 2, //size 限定返回的结果条数,from 指定起始位子,_source 指定要返回的字段
"from": 0,
"_source": [ "title", "summary", "publish_date" ],
"highlight": {
"fields" : {
"title" : {} //包含查询关键词才可以设置高亮,并且可以设置前后标签比如<strong>xxx</strong>
}
}
}
[Results]
"hits": {
"total": 2,
"max_score": 0.9105287,
"hits": [
{
"_index": "bookdb_index",
"_type": "book",
"_id": "3",
"_score": 0.9105287,
"_source": {
"summary": "build scalable search applications using Elasticsearch without having to do complex low-level programming or understand advanced data science algorithms",
"title": "Elasticsearch in Action",
"publish_date": "2015-12-03"
},
"highlight": {
"title": [
"Elasticsearch <em>in</em> <em>Action</em>"
]
}
},
{
"_index": "bookdb_index",
"_type": "book",
"_id": "4",
"_score": 0.9105287,
"_source": {
"summary": "Comprehensive guide to implementing a scalable search engine using Apache Solr",
"title": "Solr in Action",
"publish_date": "2014-04-05"
},
"highlight": {
"title": [
"Solr <em>in</em> <em>Action</em>"
]
}
}
]
}2. 多字段(Multi-filed)查询
POST /bookdb_index/book/_search
{
"query":{
"multi_match": {
"query": "guide", //根据多个字段检索相同内容
"fields": ["title","summary"]
}
}
}
[Results]
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.3278645,
"hits" : [
{
"_index" : "bookdb_index",
"_type" : "book",
"_id" : "4",
"_score" : 1.3278645,
"_source" : {
"title" : "Solr in Action",
"authors" : [
"trey grainger",
"timothy potter"
],
"summary" : "Comprehensive guide(这里) to implementing a scalable search engine using Apache Solr",
"publish_date" : "2014-04-05",
"num_reviews" : 23,
"publisher" : "manning"
}
},
{
"_index" : "bookdb_index",
"_type" : "book",
"_id" : "1",
"_score" : 1.2871116,
"_source" : {
"title" : "Elasticsearch: The Definitive Guide(这里)",
"authors" : [
"clinton gormley",
"zachary tong"
],
"summary" : "A distibuted real-time search and analytics engine",
"publish_date" : "2015-02-07",
"num_reviews" : 20,
"publisher" : "oreilly"
}
}
]
}3. Boosting(提升) ->多个字段查询下提高某字段权重
POST /bookdb_index/book/_search
{
"query":{
"multi_match": {
"query": "guide",
"fields": ["title^3","summary"]
}
}
}
[Results]
"hits" : [
{
"_index" : "bookdb_index",
"_type" : "book",
"_id" : "1",
"_score" : 3.8613348,
"_source" : {
"title" : "Elasticsearch: The Definitive Guide(title相关度提高了3倍)",
"authors" : [
"clinton gormley",
"zachary tong"
],
"summary" : "A distibuted real-time search and analytics engine",
"publish_date" : "2015-02-07",
"num_reviews" : 20,
"publisher" : "oreilly"
}
},
{
"_index" : "bookdb_index",
"_type" : "book",
"_id" : "4",
"_score" : 1.3278645,
"_source" : {
"title" : "Solr in Action",
"authors" : [
"trey grainger",
"timothy potter"
],
"summary" : "Comprehensive guide to implementing a scalable search engine using Apache Solr",
"publish_date" : "2014-04-05",
"num_reviews" : 23,
"publisher" : "manning"
}
}
]
}4. Bool查询
must是强制性的条件,文档必须满足这些条件才能被返回。must_not排除的条件是强制性排除,即使文档在其他方面匹配了查询,它也会被排除。should则是“可选”的,
如果我想要查询这样类型的书:书名包含 ElasticSearch 或者(OR) Solr,并且(AND)它的作者是 Clinton Gormley 不是(NOT)Radu Gheorge
POST /bookdb_index/book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"authors": "clinton gormely"
}
}, //必须查询出来的条件1
{
"bool": {
"should": [
{
"match": {
"title": "Elasticsearch"
}
},
{
"match": {
"title": "Solr"
}
}
]
}
} ////必须查询出来的条件2
],
"must_not": [
{
"match": {
"authors": "radu gheorge"
}
}
]
}
}
}5. 模糊(Fuzzy)查询
在进行匹配和多项匹配时,可以启用模糊匹配来捕捉拼写错误,模糊度是基于原始单词的编辑距离来指定的。
POST /bookdb_index/book/_search
{
"query": {
"multi_match" : {
"query" : "comprihensiv guide",
"fields": ["title", "summary"],
"fuzziness": "AUTO"
}
},
"_source": ["title", "summary", "publish_date"],
"size": 1
}
[Results]
"hits": [
{
"_index": "bookdb_index",
"_type": "book",
"_id": "4",
"_score": 0.5961596,
"_source": {
"summary": "Comprehensive guide to implementing a scalable search engine using Apache Solr",
"title": "Solr in Action",
"publish_date": "2014-04-05"
}
}
]注:当术语长度大于 5 个字符时,AUTO 的模糊值等同于指定值 “2”。但是,80% 拼写错误的编辑距离为 1,所以,将模糊值设置 "fuzziness": "1"可能会提高您的整体搜索性能。
6.通配符(Wildcard)查询+正则(Regexp)查询
通配符查询 允许你指定匹配的模式,而不是整个术语。
?匹配任何字符*匹配零个或多个字符
POST /bookdb_index/book/_search
{
"query": {
"wildcard": {
"authors": "t??y"
}
},
"_source": [
"title",
"authors"
],
"highlight": {
"fields": {
"authors": {}
}
}
}
{
"query": {
"regexp" : {
"authors" : "t[a-z]*y"
}
},
"_source": [
"title",
"authors"
],
"highlight": {
"fields": {
"authors": {}
}
}
}7.短语匹配(Match Phrase)查询
短语匹配查询 要求在请求字符串中的所有查询项必须都在文档中存在,文中顺序也得和请求字符串一致,且彼此相连。默认情况下,查询项之间必须紧密相连,但可以设置 slop 值来指定查询项之间可以分隔多远的距离, 这个距离是以词语的数量为单位的,结果仍将被当作一次成功的匹配。
POST /bookdb_index/book/_search
{
"query": {
"multi_match" : {
"query": "search engine",
"fields": ["title", "summary"],
"type": "phrase",
"slop": 3
}
},
"_source": [ "title", "summary", "publish_date" ]
}
[Results]
"hits": [
{
"_index": "bookdb_index",
"_type": "book",
"_id": "4",
"_score": 0.22327082,
"_source": {
"summary": "Comprehensive guide to implementing a scalable search engine using Apache Solr",
"title": "Solr in Action",
"publish_date": "2014-04-05"
}
},
{
"_index": "bookdb_index",
"_type": "book",
"_id": "1",
"_score": 0.16113183,
"_source": {
"summary": "A distibuted real-time search and analytics engine",
"title": "Elasticsearch: The Definitive Guide",
"publish_date": "2015-02-07"
}
}
]注:在上述例子中,对于非整句类型的查询,_id 为 1 的文档一般会比 _id 为 4 的文档得分高,结果位置也更靠前,因为它的字段长度较短,但是对于 短语匹配类型 查询,由于查询项之间的接近程度是一个计算因素,因此 _id 为 4 的文档得分更高。
8.短语前缀(Match Phrase Prefix)查询
match_phrase_prefix 查询是一种特殊的 短语查询,它允许你进行基于前缀的匹配,通常用于 即时搜索(search-as-you-type) 或 自动补全功能。它的主要用途是帮助用户在输入搜索词时动态地匹配文档,通常不需要额外的数据预处理。
前缀匹配:与普通的短语匹配查询(
match_phrase)不同,match_phrase_prefix允许查询某些词的前缀,而不是整个词。例如,如果查询是"autocomp",它会匹配所有以"autocomp"开头的文档内容,比如"autocomplete"、"autocompletion"等。
它接收slop 参数(用来调整单词顺序和不太严格的相对位置)和 max_expansions 参数(用来限制查询项的数量,降低对资源需求的强度)。
slop参数:
就像在 match_phrase 查询中一样,slop 在 match_phrase_prefix 查询中也起到调整单词顺序和允许一定位置偏移的作用。
slop 控制短语中词语之间可以容忍的最大距离。即使查询项之间有一些词语间隔,slop 也允许匹配。
例如,查询 "quick fox",如果设置了 slop: 1,即使 "quick" 和 "fox" 之间有一个词,Elasticsearch 也会视为匹配。
max_expansions参数:
max_expansions 控制了前缀查询可以扩展的最大次数。前缀查询会尝试匹配更多的单词变体,而 max_expansions 用来限制最多能展开多少个前缀。
例如,当你查询 "aut" 时,可能会尝试匹配 "auto", "autonomous", "automobile" 等多个变体。如果设置了 max_expansions,它会限制最多的前缀匹配数量,从而避免性能问题。
POST /bookdb_index/book/_search
{
"query": {
"match_phrase_prefix" : {
"summary": {
"query": "search en",
"slop": 3,
"max_expansions": 10
}
}
},
"_source": [ "title", "summary", "publish_date" ]
}
[Results]
"hits": [
{
"_index": "bookdb_index",
"_type": "book",
"_id": "4",
"_score": 0.5161346,
"_source": {
"summary": "Comprehensive guide to implementing a scalable search engine using Apache Solr",
"title": "Solr in Action",
"publish_date": "2014-04-05"
}
},
{
"_index": "bookdb_index",
"_type": "book",
"_id": "1",
"_score": 0.37248808,
"_source": {
"summary": "A distibuted real-time search and analytics engine",
"title": "Elasticsearch: The Definitive Guide",
"publish_date": "2015-02-07"
}
}
]注:采用 查询时即时搜索 具有较大的性能成本。更好的解决方案是采用 索引时即时搜索。更多信息,请查看 自动补齐接口(Completion Suggester API) 或 边缘分词器(Edge-Ngram filters)的用法。
9.查询字符串(Query String) --》太吊了
查询字符串 类型(query_string)的查询提供了一个方法,用简洁的简写语法来执行 多匹配查询、 布尔查询 、 提权查询、 模糊查询、 通配符查询、 正则查询 和范围查询。
假设我们有一个图书数据库,我们希望根据以下要求进行搜索:
查找标题包含
search algorithm或者与search拼写相似的词(模糊查询)。只查找作者为
grant ingersoll或tom morton的书籍。排除作者为
john doe的书籍。查找价格在
10到100之间的书籍。查找发布日期在
2015-01-01到2020-12-31之间的书籍。对
title字段设置较高的权重(^2),而对summary设置较低的权重(^1)。在
summary字段中进行通配符查询(查找包含advanced这个词的书籍)。对查询中的词项进行高亮显示。
组合查询示例:
POST /bookdb_index/book/_search
{
"query": {
"query_string": {
"query": "(search~1 OR algorithm) AND (grant ingersoll OR tom morton) NOT john doe AND price:[10 TO 100] AND date:[2015-01-01 TO 2020-12-31] AND summary:advanced*",
"fields": ["title^2", "summary^1", "authors"],
"default_operator": "AND"
}
},
"_source": ["title", "summary", "authors", "price", "date"],
"highlight": {
"fields": {
"title": {},
"summary": {}
}
}
}解析:
模糊查询:
search~1:匹配search或者拼写错误的词(如saerch)。algorithm:精确匹配algorithm。
布尔查询:
(grant ingersoll OR tom morton):匹配作者是grant ingersoll或tom morton的书籍。NOT john doe:排除作者为john doe的书籍。
范围查询:
price:[10 TO 100]:查询价格在 10 到 100 之间的书籍。date:[2015-01-01 TO 2020-12-31]:查询发布日期在2015-01-01到2020-12-31之间的书籍。
权重提升:
title^2:对title字段进行权重提升,意味着title字段的匹配结果将比其他字段更重要。summary^1:设置summary字段的默认权重(即 1),确保summary也会影响查询结果。
通配符查询:
summary:advanced*:匹配summary字段中以advanced开头的所有词,如advanced search、advanced algorithms等。
高亮显示:
高亮显示
title和summary字段,以便在结果中突出显示这些字段。
默认运算符:
default_operator: "AND":默认操作符是AND,这意味着查询项之间的默认关系是 "与"。如果你在查询字符串中没有明确指定OR或AND,系统会自动使用AND。
simple_query_string 是 query_string 查询的一个简化版本,它的主要目的是为了解决在用户输入搜索时出现的潜在错误,提供一个更简便、容错性更强的查询方式。
10.简单查询字符串(Simple Query String)
1. 简化语法
simple_query_string 替换了 query_string 中一些常见的逻辑运算符,使得语法更简单,适合普通用户使用。例如:
+替代AND|替代OR-替代NOT
这意味着用户可以在查询时输入类似 search +algorithm -error 来表示“搜索包含 search 和 algorithm,但不包含 error”。
2. 自动丢弃无效部分
simple_query_string 查询会自动忽略那些无效的查询部分,而不会抛出错误。这意味着如果用户在输入查询时犯了一些常见错误(例如拼写错误或使用了不正确的语法),simple_query_string 会尽力忽略这些问题并继续进行查询,而不会像 query_string 那样抛出异常或导致查询失败。
3. 更适合暴露给普通用户的场景
simple_query_string 的目标用户是普通用户,尤其是在搜索框中进行简单搜索时,它能够容忍用户输入的错误。例如:
用户不需要掌握复杂的查询语法(例如使用括号来分组,或者明确使用
AND、OR和NOT)。它也允许用户输入一些有误的部分而不会影响查询的执行。
假设你有一个书籍数据库,用户可以输入如下查询:
plaintext
复制编辑
search +algorithm -error这相当于:
+search:要求包含search+algorithm:要求包含algorithm-error:不包含error
对应的 simple_query_string 查询:
{
"query": {
"simple_query_string": {
"query": "search +algorithm -error",
"fields": ["title", "summary"]
}
}
}query_string支持更多的复杂功能,比如自定义运算符、通配符、正则表达式等,适合更复杂的查询需求。simple_query_string更简单,功能有限,但更加容错,不容易出错,适合提供给终端用户使用。
容错性示例
1. 拼写错误
假设用户在查询中输入了一个拼写错误的单词,比如 algorithim(应为 algorithm),使用 simple_query_string 查询时,Elasticsearch 会自动忽略这个错误并继续执行查询。
查询字符串:
search +algorithim +algorithm
查询语法:
{
"query": {
"simple_query_string": {
"query": "search +algorithim +algorithm",
"fields": ["title", "summary"]
}
}
}
结果:
Elasticsearch 会忽略
algorithim的拼写错误,实际上它会在查询中只关注algorithm,因此查询会匹配包含search和algorithm的文档。
2. 无效的逻辑运算符
如果用户输入了不正确的运算符,simple_query_string 会自动忽略这些部分,而不会抛出错误。例如,用户输入了无效的运算符(例如 &),而 simple_query_string 不支持该运算符。
查询字符串:
search &algorithm
查询语法:
{
"query": {
"simple_query_string": {
"query": "search &algorithm",
"fields": ["title", "summary"]
}
}
}
结果:
Elasticsearch 会忽略
&运算符,只会查询包含search和algorithm的文档。它不会抛出错误或失败,而是“容忍”用户的错误输入。
3. 遗漏的逻辑运算符
如果用户没有正确使用逻辑运算符,simple_query_string 会自动假设某些默认的逻辑(如 OR),而不会让查询失败。
查询字符串:
search algorithm
查询语法:
{
"query": {
"simple_query_string": {
"query": "search algorithm",
"fields": ["title", "summary"]
}
}
}
结果:
simple_query_string会默认将查询理解为search OR algorithm,因此它会返回包含search或algorithm的文档,而不是因为缺少逻辑运算符而导致查询失败。
4. 忽略额外的无效字符
如果用户在查询中包含不被支持的字符(比如特殊字符),simple_query_string 会自动忽略它们,而不会使查询失败。
查询字符串:
search +algorithm & (error
查询语法:
{
"query": {
"simple_query_string": {
"query": "search +algorithm & (error",
"fields": ["title", "summary"]
}
}
}
结果:
Elasticsearch 会忽略
&和(等无效字符,仅关注有效部分:search +algorithm。查询将会匹配包含search和algorithm的文档。它不会抛出错误,而是容忍这些无效字符。
11.词条(Term)/多词条(Terms)查询
以上例子均为 full-text(全文检索) 的示例。有时我们对结构化查询更感兴趣,希望得到更准确的匹配并返回结果,词条查询 和 多词条查询 可帮我们实现。在下面的例子中,我们要在索引中找到所有由 Manning 出版的图书。---->搭配keyword类型的mapping
POST /bookdb_index/book/_search
{
"query": {
"term" : {
"publisher": "manning"
}
},
"_source" : ["title","publish_date","publisher"]
}
[Results]
"hits": [
{
"_index": "bookdb_index",
"_type": "book",
"_id": "2",
"_score": 1.2231436,
"_source": {
"publisher": "manning",
"title": "Taming Text: How to Find, Organize, and Manipulate It",
"publish_date": "2013-01-24"
}
},
{
"_index": "bookdb_index",
"_type": "book",
"_id": "3",
"_score": 1.2231436,
"_source": {
"publisher": "manning",
"title": "Elasticsearch in Action",
"publish_date": "2015-12-03"
}
},
{
"_index": "bookdb_index",
"_type": "book",
"_id": "4",
"_score": 1.2231436,
"_source": {
"publisher": "manning",
"title": "Solr in Action",
"publish_date": "2014-04-05"
}
}
]可使用词条关键字来指定多个词条,将搜索项用数组传入。
{
"query": {
"terms" : {
"publisher": ["oreilly", "packt"]
}
}
}12.排序(Sorted)
POST /bookdb_index/book/_search
{
"query": {
"term" : {
"publisher": "manning"
}
},
"_source" : ["title","publish_date","publisher"],
"sort": [
{ "publish_date": {"order":"desc"}},
{ "title": { "order": "desc" }}
]
}
[Results]
"hits": [
{
"_index": "bookdb_index",
"_type": "book",
"_id": "3",
"_score": null,
"_source": {
"publisher": "manning",
"title": "Elasticsearch in Action",
"publish_date": "2015-12-03"
},
"sort": [
1449100800000,
"in"
]
},
{
"_index": "bookdb_index",
"_type": "book",
"_id": "4",
"_score": null,
"_source": {
"publisher": "manning",
"title": "Solr in Action",
"publish_date": "2014-04-05"
},
"sort": [
1396656000000,
"solr"
]
},
{
"_index": "bookdb_index",
"_type": "book",
"_id": "2",
"_score": null,
"_source": {
"publisher": "manning",
"title": "Taming Text: How to Find, Organize, and Manipulate It",
"publish_date": "2013-01-24"
},
"sort": [
1358985600000,
"to"
]
}
]13.范围查询
范围查询 用于日期、数字和字符串类型的字段。
POST /bookdb_index/book/_search
{
"query": {
"range" : {
"publish_date": {
"gte": "2015-01-01",
"lte": "2015-12-31"
}
}
},
"_source" : ["title","publish_date","publisher"]
}
[Results]
"hits": [
{
"_index": "bookdb_index",
"_type": "book",
"_id": "1",
"_score": 1,
"_source": {
"publisher": "oreilly",
"title": "Elasticsearch: The Definitive Guide",
"publish_date": "2015-02-07"
}
},
{
"_index": "bookdb_index",
"_type": "book",
"_id": "3",
"_score": 1,
"_source": {
"publisher": "manning",
"title": "Elasticsearch in Action",
"publish_date": "2015-12-03"
}
}
]14.过滤(Filtered)查询+多重过滤
多重过滤就相当于嵌入了bool+过滤
POST /bookdb_index/book/_search
{
"query": {
"bool": {
"must" : {
"multi_match": {
"query": "elasticsearch",
"fields": ["title","summary"]
}
},
"filter": {
"range" : {
"num_reviews": {
"gte": 20
}
}
}
}
},
"_source" : ["title","summary","publisher", "num_reviews"]
}POST /bookdb_index/book/_search
{
"query": {
"bool": {
"must": {
"multi_match": {
"query": "elasticsearch",
"fields": ["title", "summary"]
}
},
"filter": {
"bool": {
"must": {
"range": { "num_reviews": { "gte": 20 } }
},
"must_not": {
"range": { "publish_date": { "lte": "2014-12-31" } }
},
"should": {
"term": { "publisher": "oreilly" }
}
}
}
}
},
"_source": ["title", "summary", "publisher", "num_reviews", "publish_date"]
}
15.作用分值: 域值(Field Value)因子;衰变(Decay)函数
域值(Field Value)因子作用:把文档中的某个特定域作为计算相关性分值的一个因素
衰变(Decay)函数:有一个理想目标值,并希望用这个加权因子来对这个离你较远的目标值进行衰减。有个典型的用途是基于经纬度、价格或日期等数值域的提升
modifier:
定义如何修改计算后的评分值。
常见取值:
none:不做任何修饰。log/log1p/log2p:取对数。sqrt:平方根。reciprocal:计算倒数。linear/exp:线性或指数增长。
factor:
影响评分的比例因子,通常作为放大或缩小的倍数。
用法:对一个字段值或脚本计算结果进行乘法调整。
boost_mode:控制如何将原始相关性分数与计算的功能评分结合。
常见取值:
multiply:将功能评分乘以原始分数(默认)。replace:完全替换原始分数。sum:将功能评分与原始分数相加。avg:计算两者的平均值。max:取两者的最大值。min:取两者的最小值。
score_mode:定义如何合并多个函数评分结果(如果有多种评分函数)。
常见取值:
multiply/sum/avg/max/min。
可选衰减函数:
gauss(高斯函数): 平滑、渐进的衰减。exp(指数函数): 衰减速度更快。linear(线性函数): 衰减速度为线性递减。
参数:
origin
衰减的起始点(参考值)。
scale
定义影响分数的范围(多大范围内分数显著变化)。
offset
一个偏移量,定义从哪里开始衰减(在偏移量范围内分数保持不变)。
decay
控制分数的衰减程度(分数减少到多少)。
假设需求:
用户搜索书籍标题包含
Elasticsearch。价格影响分数:更高价格的书优先,但平滑放大影响。
发布日期影响分数:更近期的书优先。
出版社为 "oreilly" 的书加权。
POST /bookdb_index/_search
{
"query": {
"function_score": { // 使用 Function Score Query,自定义评分规则
"query": {
"match": { // 主查询,匹配标题包含 "Elasticsearch"
"title": "Elasticsearch" // 搜索字段是 title,查询关键字是 Elasticsearch
}
},
"functions": [ // 定义评分规则的 functions 数组
{
"field_value_factor": { // 使用字段值因子,动态调整评分
"field": "price", // 基于 price 字段的值计算分数
"factor": 0.1, // 每增加 10 单位的价格,增加 1 分
"modifier": "log1p" // 计算公式为 log(1 + field_value),平滑高值影响
}
},
{
"gauss": { // 使用高斯衰减函数调整评分
"publish_date": { // 基于 publish_date 字段进行衰减
"origin": "2023-01-01", // 起始点(基准值),2023年1月1日
"scale": "30d", // 30天内分数显著变化
"offset": "10d", // 在前 10 天内,分数不衰减
"decay": 0.5 // 超过 scale 后分数衰减到原来的一半
}
}
},
{
"filter": { // 定义额外加权的条件
"term": { // 如果满足条件
"publisher": "oreilly" // 出版社是 oreilly
}
},
"weight": 2 // 满足条件的文档,额外加权 2 分
}
],
"score_mode": "sum", // 多个评分规则的分值相加作为最终分数
"boost_mode": "sum" // 将主查询得分和 functions 的分值相加
}
},
"_source": ["title", "price", "publish_date", "publisher"] // 控制返回的字段,只返回所需的字段
}
16.函数分值: 脚本评分
略
1.3 删除文档
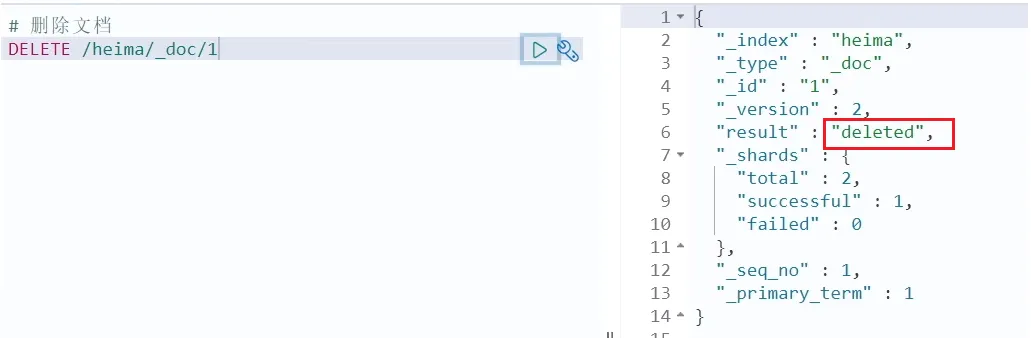
删除使用DELETE请求,同样,需要根据id进行删除:
语法:
DELETE /{索引库名}/_doc/id值示例:
# 根据id删除数据
DELETE /heima/_doc/1结果:
1.4 修改文档
修改有两种方式:
全量修改:直接覆盖原来的文档
增量修改:修改文档中的部分字段
1.4.1 全量修改
全量修改是覆盖原来的文档,其本质是:
根据指定的id删除文档
新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}示例:
PUT /heima/_doc/1
{
"info": "黑马程序员高级Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}1.4.2 增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}示例:
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@itcast.cn"
}
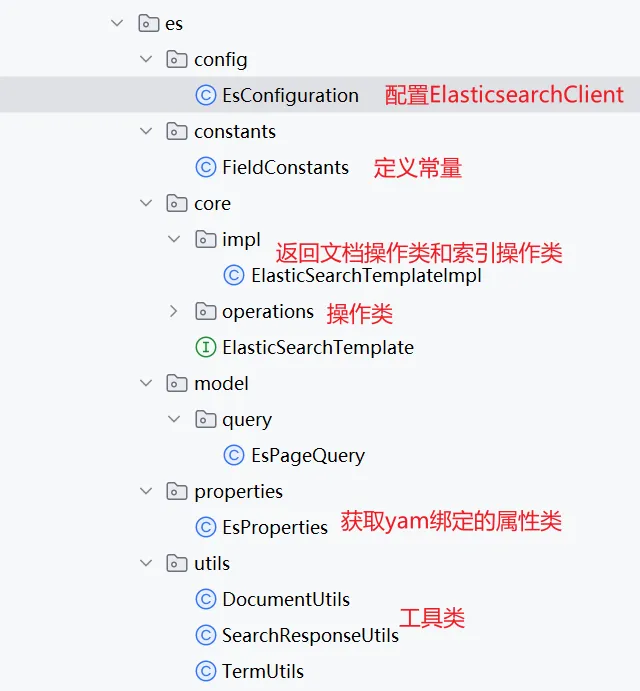
}架构设计实现
整体架构如下:
@Configuration
@EnableConfigurationProperties(EsProperties.class)
public class EsConfiguration {
private static final ObjectMapper MAPPER = new ObjectMapper();
static {
MAPPER.setPropertyNamingStrategy(PropertyNamingStrategies.SNAKE_CASE); //因为实体类是用驼峰命名,而数据库是下划线命名,所以得设置命名策略
MAPPER.setSerializationInclusion(JsonInclude.Include.NON_NULL); //过配置过滤掉 null 值,可以精简 JSON 数据,提高传输效率
/**
* springboot自动帮我们给ObjectMapper引入了javaTimeModule(处理用来支持 Java 8 引入的日期和时间 API) 但是默认的处理器使用 ISO-8601 格式(例如 "2025-02-22T23:01:18")。
*/
JavaTimeModule javaTimeModule = new JavaTimeModule();
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern(DatePattern.NORM_DATETIME_PATTERN);
javaTimeModule.addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(dateTimeFormatter)); //为LocalDateTime.class这个类设置序列化器
javaTimeModule.addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(dateTimeFormatter));//为LocalDateTime.class这个类设置反序列化器
MAPPER.registerModule(javaTimeModule); //将配置好的 JavaTimeModule 注册到 ObjectMapper 实例中
}
/*
RestClient 提供底层 HTTP 支持。
ElasticsearchTransport 提供通信抽象,将 RestClient 和 ElasticsearchClient 连接起来。
ElasticsearchClient 提供高级 API,简化应用程序与 Elasticsearch 的交互。
*/
@Bean
public ElasticsearchClient esClient(EsProperties esProperties) {
RestClient restClient = RestClient.builder(new HttpHost(esProperties.getHost(), esProperties.getPort())).build();
// 使用自定义json序列化
JacksonJsonpMapper jacksonJsonpMapper = new JacksonJsonpMapper(MAPPER);
ElasticsearchTransport transport = new RestClientTransport(restClient, jacksonJsonpMapper);
return new ElasticsearchClient(transport);
}
@Bean
public ElasticSearchTemplate template(ElasticsearchClient elasticsearchClient) {
return new ElasticSearchTemplateImpl(elasticsearchClient);
}
}@Slf4j
public class DefaultDocumentOperations implements DocumentOperations {
private final ElasticsearchClient elasticsearchClient;
public DefaultDocumentOperations(ElasticsearchClient elasticsearchClient) {
this.elasticsearchClient = elasticsearchClient;
}
@Override
public <T> Boolean insert(String index, T document) {
try {
CreateResponse createResponse = elasticsearchClient.create(builder -> builder.id(getId(document)).document(document).index(index));
log.debug("create document response : {}", createResponse);
boolean success = isSuccess(createResponse);
return success;
} catch (IOException e) {
// e.printStackTrace();
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
// return false;
}
@Override
public <T> Boolean batchInsert(String index, List<T> documents) {
BulkRequest.Builder br = new BulkRequest.Builder(); // BulkRequest是Elasticsearch 客户端提供的构建器,用来构建批量请求,Builder方便调用
for (T document : documents) {
//operations方法:将操作添加到 BulkRequest 请求--》private List<BulkOperation> operations;
br.operations(op -> op.index(idx -> idx.index(index) //index即将文档插入指定索引
.id(getId(document))
.document(document)));
}
try {
BulkResponse bulk = elasticsearchClient.bulk(br.build());
Boolean success = isSuccess(bulk);
return success;
} catch (IOException e) {
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
}
@Override
public <T> Boolean batchUpsert(String index, List<T> documents) {
// 如果输入的 documents 列表为空,则返回 false
if (CollUtils.isEmpty(documents)) {
return false;
}
// 提取所有文档的 ID
List<String> ids = documents.stream().map(document -> getId(document)).collect(Collectors.toList());
// 使用 findByIds 方法从 Elasticsearch 查询这些 ID 是否已存在,返回包含 ID 的文档
List<?> documentInEs = this.findByIds(index, ids, Arrays.asList(FieldConstants.ID), documents.get(0).getClass());
// 提取出在 Elasticsearch 中已存在的 ID
List<String> idsInEs = CollUtils.isEmpty(documentInEs) ? new ArrayList<>() :
documentInEs.stream().map(document -> getId(document)).collect(Collectors.toList());
// 创建批量请求构建器,用于批量插入或更新操作
BulkRequest.Builder builder = new BulkRequest.Builder();
// 遍历每个文档
for (T document : documents) {
String id = getId(document); // 获取文档的 ID
boolean exists = idsInEs.contains(id); // 判断该文档的 ID 是否已经存在于 Elasticsearch 中
// 为每个文档创建一个批量操作(update 或 index)
builder.operations(op -> {
if (exists) {
// 如果文档已存在,则执行更新操作(update)
op.update(u -> u.action(a -> a.doc(document)).index(index).id(id));
} else {
// 如果文档不存在,则执行插入操作(index)
op.index(idx -> idx.index(index)
.id(id)
.document(document));
}
return op; // 返回操作对象
});
}
try {
BulkResponse bulk = elasticsearchClient.bulk(builder.build());
Boolean success = isSuccess(bulk);
return success;
} catch (IOException e) {
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
}
@Override
public <T> Boolean updateById(String index, T document) {
Object id = ReflectUtils.getFieldValue(document, IdUtils.ID);
if (id == null) {
throw new ElasticSearchException("es更新失败,id为空");
}
try {
// 2.数据更新
UpdateResponse<?> response = elasticsearchClient.update(u -> u
.index(index)
.id(id.toString())
.doc(document)
, document.getClass());
Boolean success = isSuccess(response);
return success;
} catch (IOException e) {
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
}
@Override
public <ID> Boolean deleteById(String index, ID id) {
try {
// 2.数据更新
DeleteResponse response = elasticsearchClient.delete(builder -> builder.id(id.toString()).index(index));
Boolean success = isSuccess(response);
return success;
} catch (IOException e) {
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
}
@Override
public <ID> Boolean batchDelete(String index, List<ID> ids) {
BulkRequest.Builder builder = new BulkRequest.Builder();
ids.stream().forEach(id ->
builder.operations(b -> b.delete(d -> d.index(index).id(id.toString())))
);
try {
BulkResponse bulk = elasticsearchClient.bulk(builder.build());
Boolean success = isSuccess(bulk);
return success;
} catch (Exception e) {
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
}
@Override
public <T, ID> T findById(String index, ID id, Class<T> clazz) {
try {
GetResponse<T> response = elasticsearchClient.get(GetRequest.of(builder -> builder.id(id.toString()).index(index)), clazz);
return response.source();
} catch (IOException e) {
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
}
@Override
//详解参照下一个方法
public <T, ID> List<T> findByIds(String index, List<ID> ids, Class<T> clazz) {
SearchRequest.Builder searchRequestBuild = new SearchRequest.Builder();
TermsQuery termsQuery = TermsQuery.of(t -> t.field(FieldConstants.ID).terms(new TermsQueryField.Builder().value(TermUtils.parse(ids)).build()));
searchRequestBuild.index(index)
.query(builder -> builder.terms(termsQuery));
try {
SearchResponse<T> searchResponse = elasticsearchClient.search(searchRequestBuild.build(), clazz);
return searchResponse.hits().hits()
.stream()
.map(tHit -> tHit.source())
.collect(Collectors.toList());
} catch (IOException e) {
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
}
@Override
public <T, ID> List<T> findByIds(String index, List<ID> ids, List<String> fields, Class<T> clazz) {
SearchRequest.Builder searchRequestBuild = new SearchRequest.Builder(); //构建查询请求
/** TermsQuery 是 Elasticsearch 中的一种查询类型,用于在指定字段上查找多个值。
* terms:表示这是一个“多值查询”,即根据 ids 中的多个 ID 查询匹配的文档。 不过得先将ids转换成符合 Elasticsearch 要求的格式
*/
TermsQuery termsQuery = TermsQuery.of(t -> t.field(FieldConstants.ID).terms(new TermsQueryField.Builder().value(TermUtils.parse(ids)).build())); //精准匹配(多个)
searchRequestBuild.index(index)
.query(builder -> builder.terms(termsQuery));
if (CollUtils.isNotEmpty(fields)) {
//FieldAndFormat 是 Elasticsearch 中用来描述查询结果中需要返回的字段的一个对象。
List<FieldAndFormat> fieldAndFormats = fields.stream().map(field -> FieldAndFormat.of(builder -> builder.field(field))).collect(Collectors.toList());
searchRequestBuild.fields(fieldAndFormats);
}
try {
SearchResponse<T> searchResponse = elasticsearchClient.search(searchRequestBuild.build(), clazz);
return searchResponse.hits().hits()
.stream()
.map(tHit -> tHit.source())
.collect(Collectors.toList());
} catch (IOException e) {
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
}
@Override
public <T> PageResult<T> findForPage(PageQueryDTO pageQueryDTO, Class<T> targetClass) {
SearchRequest.Builder builder = new SearchRequest.Builder();
builder.from(pageQueryDTO.calFrom().intValue());
builder.size(pageQueryDTO.getPageSize().intValue());
SearchRequest searchRequest = builder.build();
try {
SearchResponse<T> search = elasticsearchClient.search(searchRequest, targetClass);
long total = search.hits().total().value();
List<T> data = search.hits().hits().stream().map(Hit::source).collect(Collectors.toList());
return PageResult.of(data,Integer.parseInt(pageQueryDTO.getPageSize()+""),pageQueryDTO.getPageNo(),total);
} catch (IOException e) {
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
}
/**
*{
* "from": 0,
* "size": 10,
* "query": {
* "bool": {
* "filter": {
* "geo_distance": {
* "distance": "10km", // 假设传入的距离是10公里
* "location_field": "location", // 地理位置字段名
* "location": {
* "lat": 40.73, // 示例的纬度
* "lon": -73.93 // 示例的经度
* },
* "distance_type": "arc"
* }
* }
* }
* },
* "sort": [
* {
* "field_name": { // 假设 sortBy 是 "field_name"
* "order": "asc" // 按升序排列
* }
* }
* ]
* }
*/
@Override
public <T> List<T> searchByWithGeo(String index, SearchRequest.Builder searchBuilder, String locationName, String location, double distance, String sortBy, Boolean isAsc, int size, Class<T> clazz) {
// 坐标,距离
searchBuilder.query(query ->
query.bool(q ->
q.filter(filter->
filter.geoDistance(geo->{
geo.distance(distance + "km");
geo.field(locationName);
geo.location(location1 -> location1.text(location));
geo.distanceType(GeoDistanceType.Arc);
return geo;}))
)
);
// 自定排序字段和排序
if(StringUtils.isNotEmpty(sortBy)){
searchBuilder.sort(sortOptionsBuilder ->
sortOptionsBuilder.field(fieldSortBuilder->{
fieldSortBuilder.field(sortBy);
fieldSortBuilder.order(BooleanUtils.isTrue(isAsc) ? SortOrder.Asc : SortOrder.Desc);
return fieldSortBuilder;
})
);
}
searchBuilder.size(size);
searchBuilder.index(index);
try {
SearchResponse<T> searchResponse = elasticsearchClient.search(searchBuilder.build(), clazz);
return searchResponse.hits().hits()
.stream()
.map(tHit -> tHit.source())
.collect(Collectors.toList());
}catch (IOException e){
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
}
@Override
public <T> SearchResponse<T> search(SearchRequest searchRequest, Class<T> clazz) {
try {
return elasticsearchClient.search(searchRequest,clazz);
}catch (IOException e){
log.error(e.getMessage(),e);
throw new CommonException(500,e.getMessage());
}
}
private boolean isSuccess(WriteResponseBase writeResponseBase) {
//todo
return writeResponseBase != null &&
(Result.Created.equals(writeResponseBase.result()) ||
Result.Deleted.equals(writeResponseBase.result()) ||
Result.Updated.equals(writeResponseBase.result()) ||
Result.NoOp.equals(writeResponseBase.result()));
}
private Boolean isSuccess(BulkResponse response) {
//todo
log.debug("bulk response : {}", JsonUtils.toJsonStr(response));
if(response.errors()) {
return false;
}
return response.items().stream()
.filter(item -> item.status() != 200)
.map(item -> false)
.findFirst().orElse(true);
}
public Boolean isSuccess(DeleteByQueryResponse deleteByQueryResponse) {
return deleteByQueryResponse.deleted() > 0;
}
/**
* 获取文档id, 如果文档中设置了id,使用文档的id,如果未设置,使用雪花算法生成
*
* @param document
* @param <T>
* @return
*/
private <T> String getId(T document) {
Object objectId = ReflectUtils.getFieldValue(document, IdUtils.ID);
if (objectId == null) {
objectId = IdUtils.objectId();
}
return objectId.toString();
}
}