




Canal+Rabbit+ES实战
本文最后更新于 2025-07-04,文章超过7天没更新,应该是已完结了~
1 配置Canal+MQ数据同步环境
1.1 配置Mysql主从同步
根据Canal的工作原理,首先需要开启MySQL主从同步。
1.在MySQL中需要创建一个用户,并授权
进入mysql容器:
docker exec -it mysql /bin/bash
-- 使用命令登录:
mysql -u root -p
-- 创建用户 用户名:canal 密码:canal
create user 'canal'@'%' identified WITH mysql_native_password by 'canal';-- 授权 .表示所有库
GRANT SELECT,REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;SELECT: 允许用户查询(读取)数据库中的数据。
REPLICATION SLAVE: 允许用户作为 MySQL 复制从库,用于同步主库的数据。
REPLICATION CLIENT: 允许用户连接到主库并获取关于主库状态的信息。
在MySQL配置文件my.cnf设置如下信息,开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式
ROW 模式表示以行为单位记录每个被修改的行的变更
修改如下:
vi /usr/mysql/conf/my.cnf
[mysqld]
#打开binlog
log-bin=mysql-bin
#选择ROW(行)模式
binlog-format=ROW
#配置MySQL replaction需要定义,不要和canal的slaveId重复
server_id=1
expire_logs_days=3
max_binlog_size = 100m
max_binlog_cache_size = 512m说明:在学习阶段为了保证足够的服务器存储空间,binlog日志最大保存100m,mysql会定时清理binlog
2、重启MySQL,查看配置信息
使用命令查看是否打开binlog模式:
SHOW VARIABLES LIKE 'log_bin';

ON表示开启binlog模式。
show variables like 'binlog_format';

当 binlog_format 的值为 row 时,表示 MySQL 服务器当前配置为使用行级别的二进制日志记录,这对于数据库复制和数据同步来说更为安全,因为它记录了对数据行的确切更改。
查看binlog日志文件列表:
SHOW BINARY LOGS;
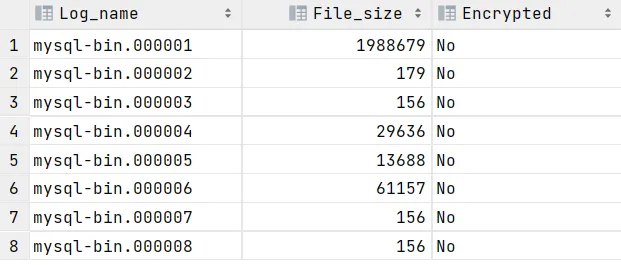
查看当前正在写入的binlog文件:
SHOW MASTER STATUS;

1.2 安装Canal(使用下发虚拟机无需安装)
获取canal镜像
docker pull canal/canal-server:latest
创建/data/soft/canal目录:
mkdir -p /data/soft/canal
在/data/soft/canal下创建 canal.properties,内容如下,注意修改mq的配置信息:
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# TCP监听的IP地址,默认绑定所有可用IP。可以根据需求指定。
# register ip to zookeeper
canal.register.ip =
# 注册到Zookeeper的IP地址。如果为空,使用canal.ip的值。
canal.port = 11111
# Canal TCP服务监听的端口,默认是11111。
canal.metrics.pull.port = 11112
# 用于Metrics监控的端口。 启用 Metrics 端口(默认 11112),通过工具监控 Canal 状态。
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# Canal实例的用户和密码(可选配置),用于对客户端进行身份验证。
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
# canal.admin.port = 11110
# 用于Admin管理页面的端口号。
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# Canal Admin的用户名和密码。
# admin auto register
#canal.admin.register.auto = true
# 是否自动注册到Canal Admin。
#canal.admin.register.cluster =
#canal.admin.register.name =
# 注册到Admin的集群和实例名称(可选配置)。
canal.zkServers =
# Zookeeper的地址,用于存储位置信息和HA(如果启用)。
canal.zookeeper.flush.period = 1000
# Canal向Zookeeper刷新信息的周期,单位为毫秒。
canal.withoutNetty = false
# 是否禁用Netty网络模块(默认false)。
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rabbitMQ
# Canal服务器的运行模式,可以是tcp、kafka、rocketMQ或rabbitMQ。
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
# 数据存储目录(例如binlog位置信息等)。
canal.file.flush.period = 1000
# 向文件中刷新的时间间隔,单位为毫秒。
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
# 内存中RingBuffer的大小,必须是2的幂,控制缓冲区的最大记录数。
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
# 每条记录的内存单位大小,默认1KB。
## memory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
# 控制RingBuffer的读取模式,可以是MEMSIZE或ITEMSIZE。
canal.instance.memory.rawEntry = true
# 是否使用原始格式存储binlog条目(true表示存储RowData格式)。
## detecing config
canal.instance.detecting.enable = false
# 是否启用连接检测。
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
# 检测连接时执行的SQL语句。
canal.instance.detecting.interval.time = 3
# 检测连接的时间间隔,单位为秒。
canal.instance.detecting.retry.threshold = 3
# 检测失败的重试次数。
canal.instance.detecting.heartbeatHaEnable = false
# 是否启用心跳检测用于高可用。
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# 支持的最大事务大小,超过此大小的事务将被分割为多个。
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# MySQL主从切换后的回退时间间隔,单位为秒。
# network config
canal.instance.network.receiveBufferSize = 16384
# 网络接收缓冲区大小,单位为字节。
canal.instance.network.sendBufferSize = 16384
# 网络发送缓冲区大小,单位为字节。
canal.instance.network.soTimeout = 30
# 网络超时时间,单位为秒。
# binlog filter config
canal.instance.filter.druid.ddl = true
# 是否过滤掉Druid解析的DDL语句。
canal.instance.filter.query.dcl = false
# 是否过滤DCL语句(如GRANT、REVOKE等)。
# 这个配置一定要修改
canal.instance.filter.query.dml = true
# 是否允许同步DML语句(INSERT、UPDATE、DELETE等)。
canal.instance.filter.query.ddl = false
# 是否允许同步DDL语句。
canal.instance.filter.table.error = false
# 是否忽略表解析错误。
canal.instance.filter.rows = false
# 是否过滤掉行级别数据。
canal.instance.filter.transaction.entry = false
# 是否过滤事务边界数据。
canal.instance.filter.dml.insert = false
# 是否过滤INSERT操作。
canal.instance.filter.dml.update = false
# 是否过滤UPDATE操作。
canal.instance.filter.dml.delete = false
# 是否过滤DELETE操作。
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
# 支持的binlog格式(ROW、STATEMENT、MIXED)。
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# 支持的binlog row image类型。
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# 是否隔离DDL操作。
# parallel parser config
canal.instance.parser.parallel = true
# 是否启用并行解析。
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
# 并行解析的线程数,建议不超过可用处理器的数量。
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# 并行解析的缓冲区大小,必须是2的幂。
# table meta tsdb info
canal.instance.tsdb.enable = true
# 是否启用表结构元数据存储。
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
# 表结构元数据的存储路径。
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
# 表结构元数据的数据库连接URL。
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# 表结构元数据的数据库用户名和密码。
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# 表结构快照的转储间隔,默认24小时。
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
# 表结构快照的过期时间,默认15天(360小时)。
#################################################
######### destinations #############
#################################################
canal.destinations = xzb-canal
# 目标实例的名称,多个实例用逗号分隔。
# conf root dir
canal.conf.dir = ../conf
# 配置文件的根目录。
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
# 是否自动扫描实例目录并启停实例。
canal.auto.scan.interval = 5
# 自动扫描的时间间隔,单位为秒。
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
# 是否跳过未找到的binlog位置并重置到最新位置(生产环境建议保持false)。
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
# 表结构元数据的Spring XML配置文件路径(H2数据库)。
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
# 表结构元数据的Spring XML配置文件路径(MySQL数据库)。
canal.instance.global.mode = spring
# 全局配置模式,默认为Spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=
canal.mq.flatMessage = true #如果 canal.mq.flatMessage 设置为 true,消费端的消息解析必须以 JSON 格式进行。如果消费端不支持 JSON 格式解析,可以设置为 false。
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host = 192.168.101.68
rabbitmq.virtual.host = /xzb
rabbitmq.exchange = exchange.canal-jzo2o
rabbitmq.username = xzb
rabbitmq.password = xzb
rabbitmq.deliveryMode = 2
创建instance.properties,内容如下:
canal.instance.master.journal.name 用于指定主库正在写入的 binlog 文件的名称。
如果不配置 canal.instance.master.journal.name,Canal 会尝试自动检测 MySQL 主库的 binlog 文件,并从最新位置开始进行复制。
#################################################
## MySQL serverId , v1.0.26+ will autoGen
canal.instance.mysql.slaveId=1000 # Canal实例的唯一标识符,避免多个实例间冲突。千万不能和mysql配置的slaveId冲突
# enable gtid use true/false
canal.instance.gtidon=false # 是否启用GTID模式,同步基于GTID的Binlog。
# position info
canal.instance.master.address=192.168.101.68:3306 # MySQL主库的地址和端口。
canal.instance.master.journal.name=mysql-bin.000001 # 从指定的Binlog文件开始读取。
canal.instance.master.position=0 # Binlog读取的初始位置。
canal.instance.master.timestamp= # 使用时间戳定位读取位置,留空则忽略。
canal.instance.master.gtid= # 使用GTID定位读取位置,留空则忽略。
# rds oss binlog
canal.instance.rds.accesskey= # RDS服务的访问密钥(如果使用RDS OSS Binlog)。
canal.instance.rds.secretkey= # RDS服务的访问密钥(如果使用RDS OSS Binlog)。
canal.instance.rds.instanceId= # RDS实例ID。
# table meta tsdb info
canal.instance.tsdb.enable=true # 是否启用表结构元数据的时间序列数据库(TSDB)。
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb # TSDB数据库的连接URL。
#canal.instance.tsdb.dbUsername=canal # TSDB数据库的用户名。
#canal.instance.tsdb.dbPassword=canal # TSDB数据库的密码。
#canal.instance.standby.address = # 备用MySQL主库地址。
#canal.instance.standby.journal.name = # 备用MySQL主库的Binlog文件名。
#canal.instance.standby.position = # 备用MySQL主库的Binlog位置。
#canal.instance.standby.timestamp = # 备用MySQL主库的时间戳位置。
#canal.instance.standby.gtid = # 备用MySQL主库的GTID位置。
# username/password
canal.instance.dbUsername=canal # Canal连接MySQL的用户名。
canal.instance.dbPassword=canal # Canal连接MySQL的密码。
canal.instance.connectionCharset=UTF-8 # Canal连接MySQL使用的字符集。
# enable druid Decrypt database password
canal.instance.enableDruid=false # 是否启用Druid解密数据库密码。
#canal.instance.pwdPublicKey= # 如果启用Druid解密,这里填写加密用的公钥。
# table regex
# canal.instance.filter.regex=test01\\..*,test02\\..* # 需要同步的表的正则匹配规则。
#canal.instance.filter.regex=test01\\..*,test02\\.t1
#canal.instance.filter.regex=jzo2o-foundations\\.serve_sync,jzo2o-orders-0\\.orders_seize,jzo2o-orders-0\\.orders_dispatch,jzo2o-orders-0\\.serve_provider_sync,jzo2o-customer\\.serve_provider_sync
canal.instance.filter.regex=jzo2o-orders-1\\.orders_dispatch,jzo2o-orders-1\\.orders_seize,jzo2o-foundations\\.serve_sync,jzo2o-customer\\.serve_provider_sync,jzo2o-orders-1\\.serve_provider_sync,jzo2o-orders-1\\.history_orders_sync,jzo2o-orders-1\\.history_orders_serve_sync,jzo2o-market\\.activity # 需要同步的表的精确匹配规则,多个表用逗号分隔。
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.* # 排除同步的表的正则规则。
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch # 只同步指定的字段。
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch # 排除同步的字段。
# mq config
#canal.mq.topic=topic_test01 # 指定MQ的Topic名称。
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..* # 动态生成Topic,按库或表的正则分组。
#canal.mq.dynamicTopic=topic_test01:test01\\..*,topic_test02:test02\\..*
#canal.mq.dynamicTopic=canal-mq-jzo2o-orders-dispatch:jzo2o-orders-0\\.orders_dispatch,canal-mq-jzo2o-orders-seize:jzo2o-orders-0\\.orders_seize,canal-mq-jzo2o-foundations:jzo2o-foundations\\.serve_sync,canal-mq-jzo2o-customer-provider:jzo2o-customer\\.serve_provider_sync,canal-mq-jzo2o-orders-provider:jzo2o-orders-0\\.serve_provider_sync
canal.mq.dynamicTopic=canal-mq-jzo2o-orders-dispatch:jzo2o-orders-1\\.orders_dispatch,canal-mq-jzo2o-orders-seize:jzo2o-orders-1\\.orders_seize,canal-mq-jzo2o-foundations:jzo2o-foundations\\.serve_sync,canal-mq-jzo2o-customer-provider:jzo2o-customer\\.serve_provider_sync,canal-mq-jzo2o-orders-provider:jzo2o-orders-1\\.serve_provider_sync,canal-mq-jzo2o-orders-serve-history:jzo2o-orders-1\\.history_orders_serve_sync,canal-mq-jzo2o-orders-history:jzo2o-orders-1\\.history_orders_sync,canal-mq-jzo2o-market-resource:jzo2o-market\\.activity # 根据不同的表动态生成对应的MQ Topic。
canal.mq.partition=0 # MQ的分区ID,默认0。
# hash partition config
#canal.mq.partitionsNum=3 # MQ的分区数量。
#canal.mq.partitionHash=test.table:id^name,.*\\..* # 使用字段生成哈希值确定分区。
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6 # 动态设置每个Topic的分区数量。
#################################################canal.instance.filter.regex需要监听的mysql库和表
全库:
.*\\..*指定库下的所有表:
canal\\..*指定库下的指定表:
canal\\.canal,test\\.test
库名\\.表名:转义需要用\\,使用逗号分隔多个库
这里配置监听 jzo2o-foundations数据库下serve_sync表,如下:
canal.instance.filter.regex=jzo2o-foundations\\.serve_sync3、在Canal配置MQ的topic
这里使用动态topic,格式为:topic:schema.table,topic:schema.table,topic:schema.table
配置如下:
canal.mq.dynamicTopic=canal-mq-jzo2o-foundations:jzo2o-foundations\\.serve_sync上边的配置表示:对jzo2o-foundations数据库的serve_sync表的修改消息发到topic为canal-mq-jzo2o-foundations关联的队列
TSDB(Table Schema Database) 是 Canal 中用于管理和存储表结构元数据(table schema metadata)的组件。它的主要作用是保存和维护目标 MySQL 数据库中表结构的历史快照和当前状态,以便 Canal 在解析 Binlog 时可以正确地映射字段。
为什么需要 TSDB?
Binlog 的特性:
MySQL 的 Binlog 文件只记录了数据的变更操作(如INSERT、UPDATE和DELETE),但不包含表结构的信息。
例如:
UPDATE users SET name='Alice' WHERE id=1;
在 Binlog 中只会存储字段的位置(如 field[1]=Alice),并不会包含字段的名称 name 或数据类型。
表结构可能发生变化:
当表结构发生变更(如添加字段、修改字段类型),Canal 需要一个机制来匹配当前的表结构,否则会导致数据解析错误。TSDB 的作用:
TSDB 用来存储表结构的历史快照,确保 Canal 在解析不同时间点的 Binlog 时,能够使用正确的表结构信息。
TSDB 的配置与作用
canal.instance.tsdb.enable=true
启用 TSDB 功能,Canal 将保存表结构快照。
canal.instance.tsdb.url
TSDB 的存储位置(默认使用 H2 内存数据库)。可以设置为外部数据库(如 MySQL)。
canal.instance.tsdb.snapshot.interval=24
每隔多少小时生成一次表结构快照(单位:小时)。
canal.instance.tsdb.snapshot.expire=360
快照保留的时间,超过这个时间的快照会被清理(单位:小时)。
总结:
TSDB 是 Canal 用来管理表结构的元数据存储机制。它的作用是保证 Canal 在解析 Binlog 时使用正确的表结构。如果不启用 TSDB,Canal 可能会在表结构变更后解析失败或数据错误。
创建日志目录:
mkdir -p /data/soft/canal/logs /data/soft/canal/conf
启动容器:
docker run --name canal -p 11111:11111 -d \
-v /data/soft/canal/instance.properties:/home/admin/canal-server/conf/xzb-canal/instance.properties \
-v /data/soft/canal/canal.properties:/home/admin/canal-server/conf/canal.properties \
-v /data/soft/canal/logs:/home/admin/canal-server/logs/xzb-canal \
-v /data/soft/canal/conf:/home/admin/canal-server/conf/xzb-canal \
canal/canal-server:latest1.3 安装RabbitMQ(使用下发虚拟机无需安装)
拉取镜像(如果未拉取过镜像)
docker pull registry.cn-hangzhou.aliyuncs.com/itheima/rabbitmq:3.9.17-management-delayed
此镜像包含了 RabbitMQ 的管理插件以及对延迟队列的支持。
创建文件夹和文件
mkdir -p /data/soft/rabbitmq/config /data/soft/rabbitmq/data /data/soft/rabbitmq/plugins
启动容器
docker run \
--privileged \
-e RABBITMQ_DEFAULT_USER=czri \
-e RABBITMQ_DEFAULT_PASS=czri1234 \
--restart=always \
--name rabbitmq \
--hostname rabbitmq \
-v /data/soft/rabbitmq/config:/etc/rabbitmq \
-v /data/soft/rabbitmq/data:/var/lib/rabbitmq \
-p 15672:15672 \
-p 5672:5672 \
-d \
registry.cn-hangzhou.aliyuncs.com/itheima/rabbitmq:3.9.17-management-delayed启动rabbitmq管理端
进入rabbitmq容器:docker exec -it rabbitmq /bin/bash
运行下边的命令:
# 启动rabbitmq管理端
rabbitmq-plugins enable rabbitmq_management
# 启动延迟队列插件
rabbitmq-plugins enable rabbitmq_delayed_message_exchange5、进入rabbitmq管理界面
http://192.168.101.68:15672/
账号:czri
密码:czri1234
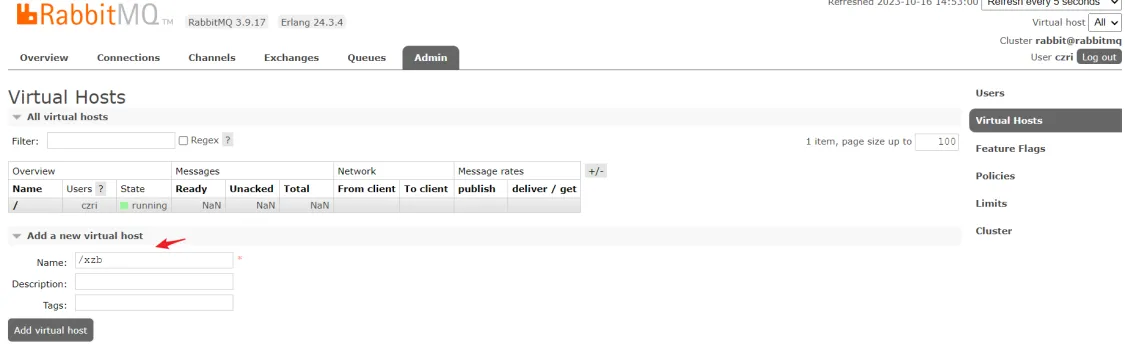
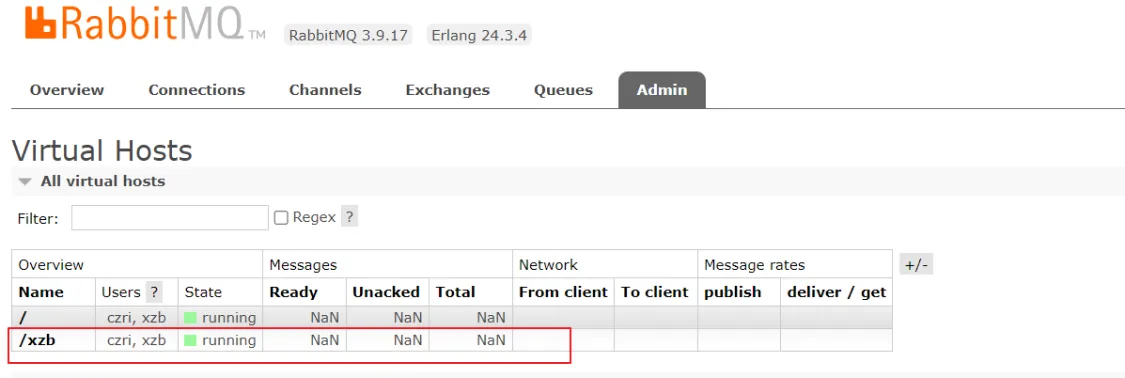
6、创建虚拟主机 /xzb
7、创建账号和密码
xzb/xzb
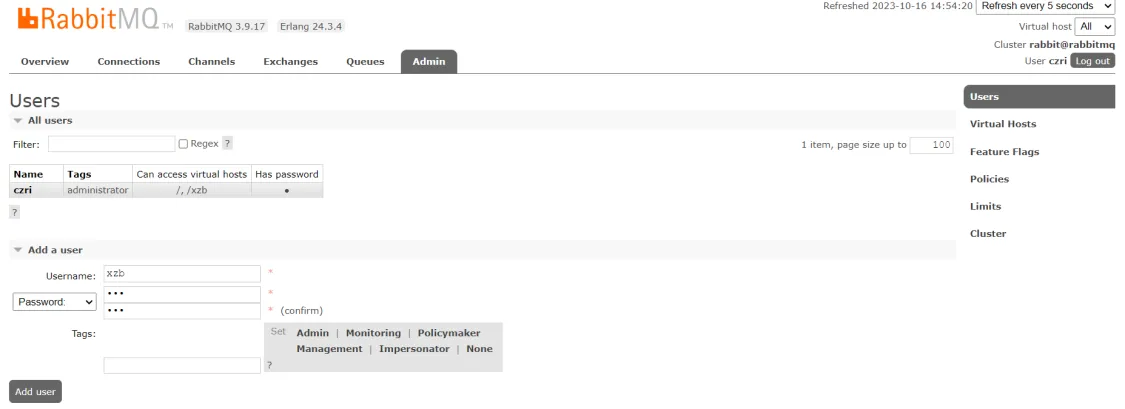
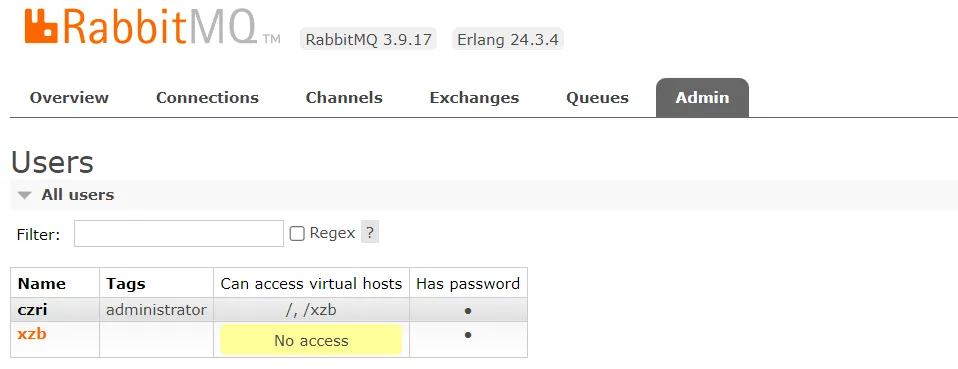
设置权限可以访问/ /xzb
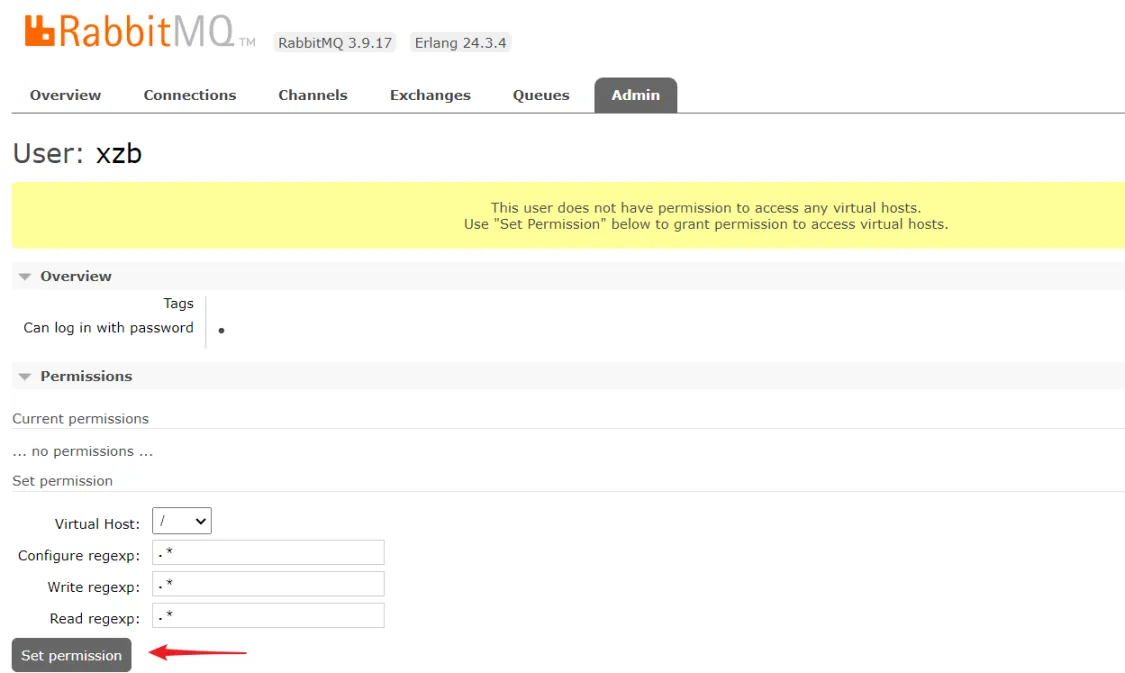
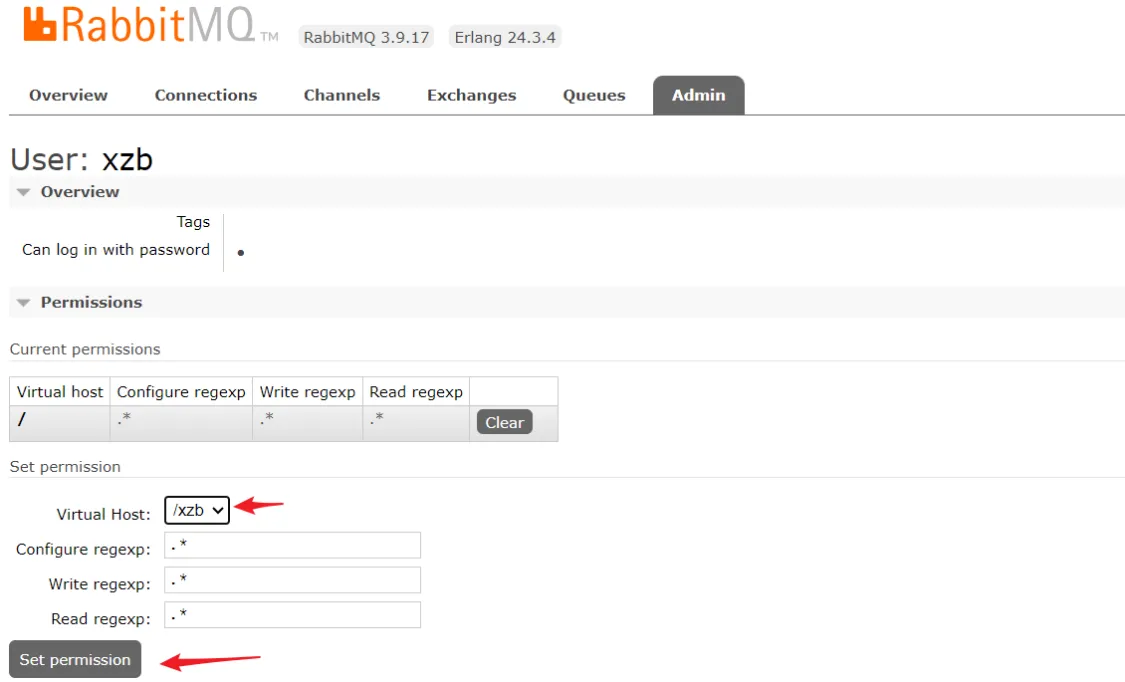
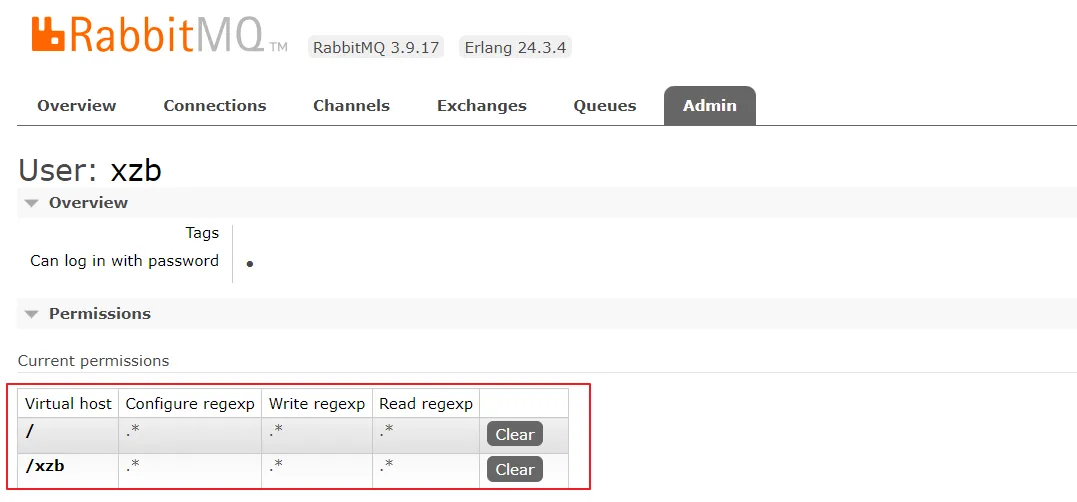
设置成功:
1.4 配置Canal+RabbitMQ
下边通过配置Canal与RabbitMQ,保证Canal收到binlog消息将数据发送至MQ。
最终我们要实现的是:
修改jzo2o-foundations数据库下的serve_sync表的数据后通过canal将修改信息发送到MQ。
1、在Canal中配置RabbitMQ的连接信息
修改/data/soft/canal/canal.properties
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rabbitMQ
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host = 192.168.101.68
rabbitmq.virtual.host = /xzb
rabbitmq.exchange = exchange.canal-jzo2o
rabbitmq.username = xzb
rabbitmq.password = xzb
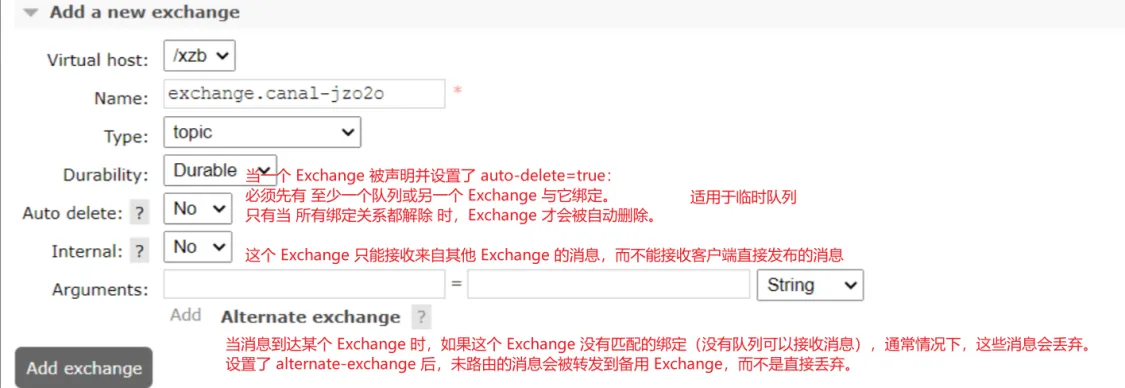
rabbitmq.deliveryMode = 2本项目用于数据同步的MQ交换机:exchange.canal-jzo2o
虚拟主机地址:/xzb
账号和密码:xzb/xzb
rabbitmq.deliveryMode = 2 设置消息持久化
2、设置需要监听的mysql库和表
修改/data/soft/canal/instance.properties
canal.instance.filter.regex需要监听的mysql库和表
全库:
.*\\..*指定库下的所有表:
canal\\..*指定库下的指定表:
canal\\.canal,test\\.test
库名\\.表名:转义需要用\\,使用逗号分隔多个库
这里配置监听 jzo2o-foundations数据库下serve_sync表,如下:
canal.instance.filter.regex=jzo2o-foundations\\.serve_sync3、在Canal配置MQ的topic
这里使用动态topic,格式为:topic:schema.table,topic:schema.table,topic:schema.table
配置如下:
canal.mq.dynamicTopic=canal-mq-jzo2o-foundations:jzo2o-foundations\\.serve_sync上边的配置表示:对jzo2o-foundations数据库的serve_sync表的修改消息发到topic为canal-mq-jzo2o-foundations关联的队列
4、进入rabbitMQ配置交换机和队列
创建exchange.canal-jzo2o交换机:
创建队列:canal-mq-jzo2o-foundations
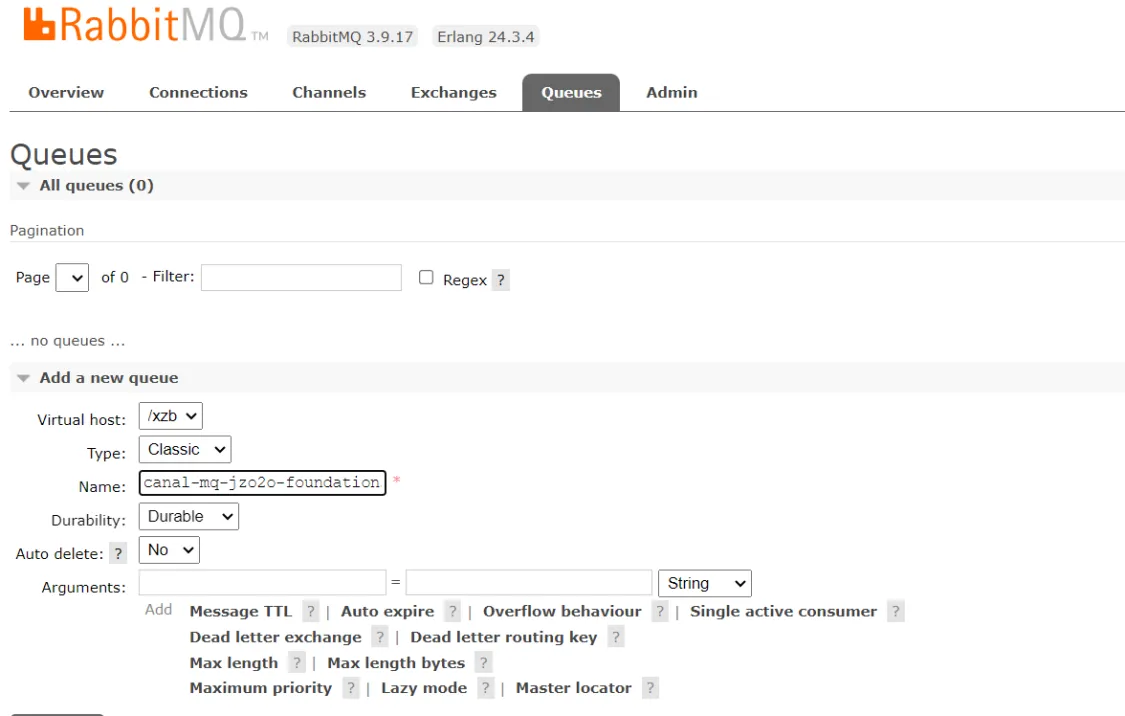
type 字段是指队列的类型,不同类型的队列有不同的消息存储方式和行为。RabbitMQ 中常见的队列类型如下:
classic
描述:classic 队列是 RabbitMQ 的默认队列类型,它是最常见的一种类型,消息会存储在内存和磁盘上,保证消息的可靠性。
特点:
适用于大多数应用场景,提供了可靠的消息存储和高效的性能。
支持持久化,消息可以在队列消费后保留,也可以在重启后恢复。
支持优先级队列。quorum
描述:quorum 队列是一种基于 Raft 协议的高可用队列,旨在提供更高的可靠性,特别是当 RabbitMQ 节点发生故障时,quorum 队列能够更好地保证消息不会丢失。
特点:
强一致性:使用 Raft 协议确保多节点间的强一致性,适合高可靠性场景。
高可用性:消息会被多个节点存储,并且支持节点间的数据复制。
恢复能力:即使某个节点失效,也能从其他节点恢复数据。
没有消息优先级:quorum 队列不支持消息优先级。
性能问题:由于强一致性,quorum 队列的性能比 classic 队列稍低,尤其是在高并发场景下。lazy
描述:lazy 队列会将消息存储在磁盘上,减少内存的占用,适用于存储大量消息的场景。消息在队列中存储时不会立即加载到内存中,只有在消费时才会加载。
特点:
低内存使用:消息优先存储在磁盘上,内存占用非常低。
性能较低:由于需要频繁从磁盘加载消息,因此相较于 classic 队列,lazy 队列在性能上可能有所下降。
适用场景:适合于存储大量消息且对内存占用有严格要求的场景,常用于数据存储密集型的应用。stream
描述:stream 队列是 RabbitMQ 在较新的版本中引入的队列类型,专为流式数据处理设计。它支持高效的顺序消息存储,并能处理大量数据流。
特点:
高效流式存储:专为流式数据处理设计,适用于高吞吐量的消息队列应用。
与 classic 队列的区别:stream 队列可以通过读取数据流的方式高效地处理消息,而不是依赖传统的队列机制。
内存和磁盘结合存储:消息会根据需要存储在内存或磁盘中,以优化性能。
RabbitMQ 队列的配置参数
Message TTL (消息TTL)
描述:设置消息在队列中的最大存活时间(TTL)。超出该时间后,消息会自动过期并被删除。
类型:整数,单位是毫秒。
用途:用于限制消息在队列中的存活时间,防止老旧消息堆积,占用队列空间。Auto expire (自动过期)
描述:设置队列本身的过期时间。如果队列在指定时间内没有被使用,或者没有消费者连接,则队列会自动删除。
类型:整数,单位是毫秒。
用途:对于临时队列或短期使用的队列,可以设置自动过期,避免浪费系统资源。Overflow behaviour (溢出行为)
描述:当队列达到最大长度时,RabbitMQ 处理消息的策略。常见的溢出行为有:
drop-head:丢弃最旧的消息。
drop-tail:丢弃最新的消息。
reject-publish:拒绝新消息的发布(直接丢弃)。
reject-publish-dlx:将被拒绝的消息发送到死信交换机(DLX)。
用途:当队列存储空间满时,决定应该如何丢弃消息或进行处理。Single active consumer (单活消费者)
描述:确保队列中只能有一个活跃消费者。如果设置为 true,RabbitMQ 会保证每次只有一个消费者从队列中消费消息。这通常用于防止多个消费者竞争同一消息的情况。
用途:适用于处理需要独占消费的任务场景,例如处理分配任务或消息的顺序性要求。Dead letter exchange (死信交换机)
描述:设置死信交换机(DLX)。当队列中的消息因为过期、拒绝或无法消费时,这些消息将被发送到死信交换机。死信交换机通常用于保存错误的、需要特殊处理的消息。
用途:可以将无法处理的消息转发到指定的死信交换机,避免丢失数据,并允许后续处理或人工干预。Dead letter routing key (死信路由键)
描述:设置死信消息的路由键。当消息被发送到死信交换机时,x-dlx 会指定消息的路由键。这是将死信消息路由到特定队列的关键。
用途:确保死信消息在死信交换机中按照特定的路由规则进行转发,便于后续处理或记录。Max length (最大消息长度)
描述:设置队列能够存储的最大消息数量。当队列中消息数量达到该值时,RabbitMQ 会根据设定的溢出行为丢弃最旧的消息。
类型:整数,表示最大消息数。
用途:可以防止队列无限制堆积消息,避免内存溢出或磁盘空间被占满。Max length bytes (最大字节数)
描述:设置队列能够存储的最大字节数。当队列中的消息总字节数达到该值时,RabbitMQ 会根据溢出行为丢弃最旧的消息。
类型:整数,单位是字节。
用途:用于控制队列的大小,防止某些队列存储过大的数据,导致系统资源被耗尽。Maximum priority (最大优先级)
描述:设置队列的最大优先级。启用优先级队列后,可以为每个消息指定一个优先级值,优先级较高的消息会优先被消费者消费。
类型:整数,表示最大优先级(通常从 0 到该值的范围)。
用途:适用于需要根据消息重要性顺序处理的场景。例如,优先处理紧急任务、重要数据等。Lazy mode (懒队列模式)
描述:启用懒队列模式,消息会尽量存储在磁盘中,减少内存占用。消费者请求时才会从磁盘加载消息到内存中。
用途:适用于对内存要求较高的环境,或者消息消费不频繁但需要存储大量消息的场景。通过将消息存储到磁盘,减少了内存占用,但可能增加消息消费的延迟。Master locator (主队列定位器)
描述:设置队列在集群中的主节点选择策略。常见的选项有:
min-masters:选择最少主节点的策略。
client-local:根据消费者的本地节点选择主队列。
random:随机选择一个主队列。
用途:用于分布式环境中队列的主节点选择,影响消息的存储和消费性能。
绑定交换机:
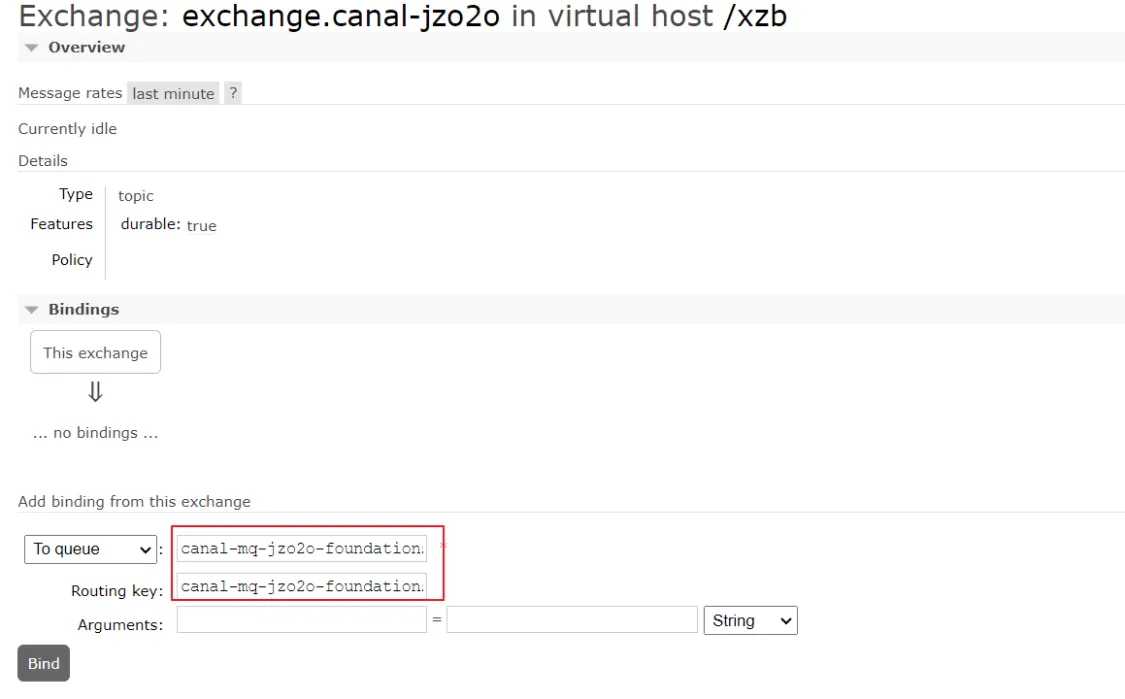
绑定成功:
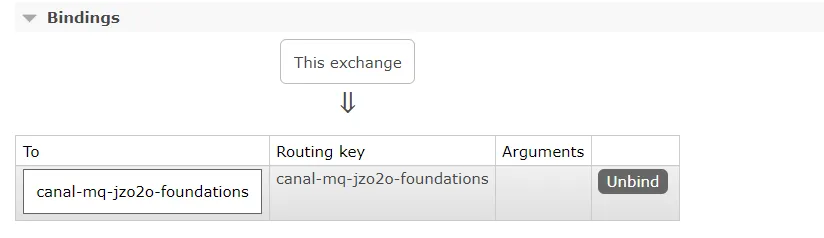
1.5 测试数据同步
重启canal
修改jzo2o-foundations数据库的serve_sync表的数据,稍等片刻查看canal-mq-jzo2o-foundations队列,如果队列中有的消息说明同步成功,如下 图:

如果没有同步到 MQ参考常见问题中“数据不同步”进行解决。
我们可以查询队列中的消息内容发现它一条type为"UPDATE"的消息,如下所示:
{
"data" : [
{
"city_code" : "010",
"detail_img" : "https://yjy-xzbjzfw-oss.oss-cn-hangzhou.aliyuncs.com/be1449d6-1c2d-4cca-9f8a-4b562b79998d.jpg",
"hot_time_stamp" : "1692256062300",
"id" : "1686352662791016449",
"is_hot" : "1",
"price" : "5.0",
"serve_item_icon" : "https://yjy-xzbjzfw-oss.oss-cn-hangzhou.aliyuncs.com/8179d29c-6b85-4c08-aa13-08429a91d86a.png",
"serve_item_id" : "1678727478181957634",
"serve_item_img" : "https://yjy-xzbjzfw-oss.oss-cn-hangzhou.aliyuncs.com/9b87ab7c-9592-4090-9299-5bcf97409fb9.png",
"serve_item_name" : "日常维修ab",
"serve_item_sort_num" : "6",
"serve_type_icon" : "https://yjy-xzbjzfw-oss.oss-cn-hangzhou.aliyuncs.com/c8725882-1fa7-49a6-94ab-cac2530b3b7b.png",
"serve_type_id" : "1678654490336124929",
"serve_type_img" : "https://yjy-xzbjzfw-oss.oss-cn-hangzhou.aliyuncs.com/00ba6d8a-fd7e-4691-8415-8ada95004b33.png",
"serve_type_name" : "日常维修12",
"serve_type_sort_num" : "2",
"unit" : "1"
}
],
"database" : "jzo2o-foundations",
"es" : 1697443035000.0,
"id" : 1,
"isDdl" : false,
"mysqlType" : {
"city_code" : "varchar(20)",
"detail_img" : "varchar(255)",
"hot_time_stamp" : "bigint",
"id" : "bigint",
"is_hot" : "int",
"price" : "decimal(10,2)",
"serve_item_icon" : "varchar(255)",
"serve_item_id" : "bigint",
"serve_item_img" : "varchar(255)",
"serve_item_name" : "varchar(100)",
"serve_item_sort_num" : "int",
"serve_type_icon" : "varchar(255)",
"serve_type_id" : "bigint",
"serve_type_img" : "varchar(255)",
"serve_type_name" : "varchar(255)",
"serve_type_sort_num" : "int",
"unit" : "int"
},
"old" : [
{
"serve_item_name" : "日常维修a"
}
],
"pkNames" : [ "id" ],
"sql" : "",
"sqlType" : {
"city_code" : 12,
"detail_img" : 12,
"hot_time_stamp" : -5,
"id" : -5,
"is_hot" : 4,
"price" : 3,
"serve_item_icon" : 12,
"serve_item_id" : -5,
"serve_item_img" : 12,
"serve_item_name" : 12,
"serve_item_sort_num" : 4,
"serve_type_icon" : 12,
"serve_type_id" : -5,
"serve_type_img" : 12,
"serve_type_name" : 12,
"serve_type_sort_num" : 4,
"unit" : 4
},
"table" : "serve_sync",
"ts" : 1697443782457.0,
"type" : "UPDATE"
}数据不同步
当发现修改了数据库后修改的数据并没有发送到MQ,通过查看Canal的日志发现下边的错误。
进入Canal目录,查看日志:
cd /data/soft/canal/logs
tail -f logs/xzb-canal.logCanal报错如下:
2023-09-22 08:34:40.802 [destination = xzb-canal , address = /192.168.101.68:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=mysql-bin.000055,position=486221,serverId=1,gtid=,timestamp=1695341830000] cost : 13ms , the next step is binlog dump
2023-09-22 08:34:40.811 [destination = xzb-canal , address = /192.168.101.68:3306 , EventParser] ERROR c.a.o.canal.parse.inbound.mysql.dbsync.DirectLogFetcher - I/O error while reading from client socket
java.io.IOException: Received error packet: errno = 1236, sqlstate = HY000 errmsg = Could not find first log file name in binary log index file
at com.alibaba.otter.canal.parse.inbound.mysql.dbsync.DirectLogFetcher.fetch(DirectLogFetcher.java:102) ~[canal.parse-1.1.5.jar:na]
at com.alibaba.otter.canal.parse.inbound.mysql.MysqlConnection.dump(MysqlConnection.java:238) [canal.parse-1.1.5.jar:na]
at com.alibaba.otter.canal.parse.inbound.AbstractEventParser$1.run(AbstractEventParser.java:262) [canal.parse-1.1.5.jar:na]
at java.lang.Thread.run(Thread.java:748) [na:1.8.0_181]找到关键的位置:Could not find first log file name in binary log index file
根据日志分析是Canal找不到mysql-bin.000055 的486221位置,原因是mysql-bin.000055文件不存在,这是由于为了节省磁盘空间将binlog日志清理了。
解决方法:
把canal复位从最开始开始同步的位置。
1)首先重置mysql的bin log:
连接mysql执行:reset master
执行后所有的binlog删除,从000001号开始
通过show master status;查看 ,结果显示 mysql-bin.000001
2)先停止canal
docker stop canal
3)删除meta.dat
rm -rf /data/soft/canal/conf/meta.dat
4) 再启动canal
docker start canal
MQ同步消息无法消费
这里以Es和MySQL之间的同步举例:
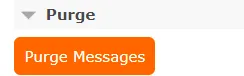
当出现ES和MySQL数据不同步时可能会出现MQ的同步消息无法被消费,比如:从MySQL删除一条记录通过同步程序将ES中对应的记录进行删除,此时由于ES中没有该记录导致删除ES中的记录失败。出现此问题的原因是因为测试数据混乱导致,可以手动将MQ中的消息删除。
进入MQ的管理控制台,进入要清理消息的队列,通过purge功能清理消息:
2 配置Elasticsearch数据同步环境
Elasticsearch7.17.7
拉取镜像
docker pull elasticsearch:7.17.7
创建文件夹:
mkdir -p /data/soft/es7.17.7/xzb
在/data/soft/es7.17.7/xzb下创建data目录并且修改权限为777
mkdir data
chmod 777 data将课程资料下的"ES安装"目录中的 es.zip上传到/data/soft/es7.17.7/xzb下,并进行解压
unzip es.zip解压成功如下图:
创建容器
docker run -d \
--name elasticsearch7.17.7 \
--restart always \
-p 9200:9200 \
-p 9300:9300 \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-v /data/soft/es7.17.7/xzb/data:/usr/share/elasticsearch/data \
-v /data/soft/es7.17.7/xzb/plugins:/usr/share/elasticsearch/plugins \
-v /data/soft/es7.17.7/xzb/config:/usr/share/elasticsearch/config \
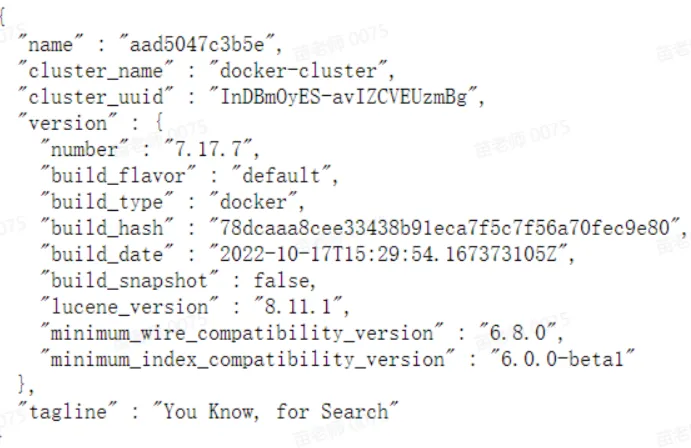
elasticsearch:7.17.7访问http://192.168.101.68:9200/,如下图说明启动成功:
kibana7.17.7
拉取镜像
docker pull kibana:7.17.7
创建容器:
注意修改es的地址
docker run --name kibana7.17.7 \
-e ELASTICSEARCH_HOSTS=http://192.168.101.68:9200 \
-p 5601:5601 \
-d kibana:7.17.7下边启动容器,先保证Elasticsearch启动成功。
启动kibana容器成功,在浏览器输入地址访问:http://192.168.101.68:5601,进入DevTools,如下图:
执行:GET /_cat/indices?v 查询索引信息
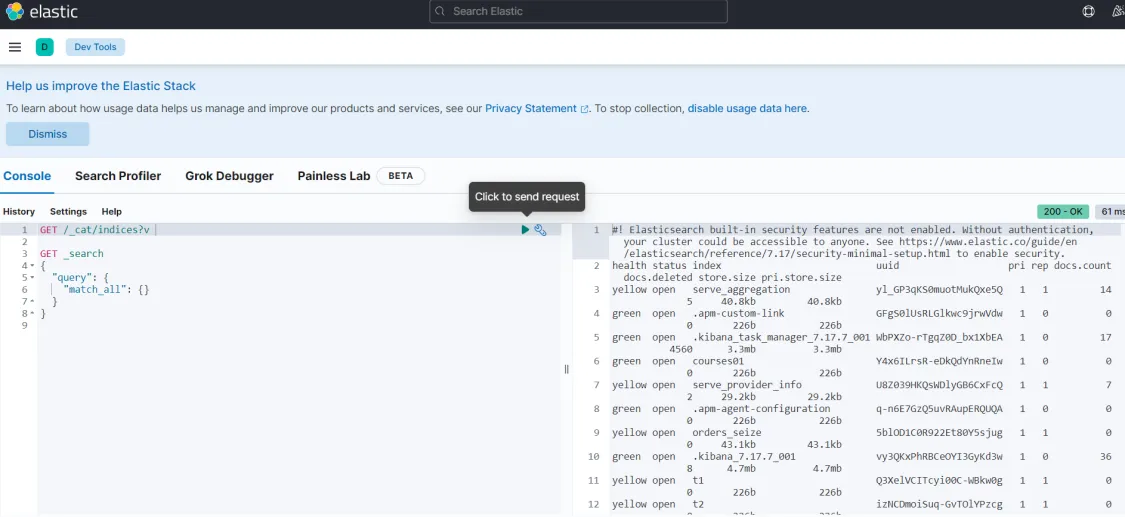
创建项目所需要的索引结构
启动ES和kibana:
如果没有安装参考本文档 安装elasticsearch7.17.7 和 kibana7.17.7。
安装完成后进行启动:
docker start elasticsearch7.17.7
docker start kibana7.17.7本项目共需创建下边三个索引结构:
首先通过下边的命令查询索引
GET /_cat/indices?v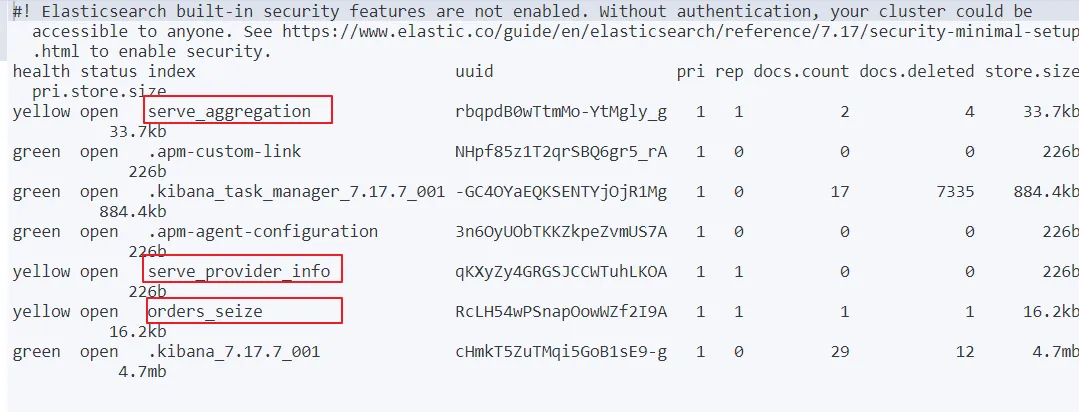
创建orders_seize和serve_provider_info(已经存在无法重复创建)
PUT /serve_provider_info
{
"mappings" : {
"properties" : {
"acceptance_num" : {
"type" : "integer"
},
"city_code" : {
"type" : "keyword"
},
"evaluation_score" : {
"type" : "double"
},
"id" : {
"type" : "long"
},
"location" : {
"type" : "geo_point"
},
"pick_up" : {
"type" : "integer"
},
"serve_item_ids" : {
"type" : "long"
},
"serve_provider_type" : {
"type" : "integer"
},
"serve_times" : {
"type" : "integer"
},
"setting_status" : {
"type" : "long"
},
"settting_status" : {
"type" : "integer"
},
"skills" : {
"type" : "long"
}
}
}
}如果需要修改索引结构需要删除重新创建:
DELETE 索引名查询索引结构
GET /索引名/_mapping下边继续创建其它索引:
创建:orders_seize (已经存在无法重复创建)
PUT /orders_seize
{
"mappings" : {
"properties" : {
"city_code" : {
"type" : "keyword"
},
"id" : {
"type" : "long"
},
"key_words" : {
"type" : "text",
"analyzer" : "ik_max_word",
"search_analyzer" : "ik_smart"
},
"location" : {
"type" : "geo_point"
},
"orders_amount" : {
"type" : "float"
},
"pur_num" : {
"type" : "integer"
},
"serve_address" : {
"type" : "text",
"index" : false
},
"serve_item_id" : {
"type" : "long"
},
"serve_item_img" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"serve_item_name" : {
"type" : "text",
"index" : false
},
"serve_start_time" : {
"type" : "text",
"index" : false
},
"serve_time" : {
"type" : "integer"
},
"serve_type_id" : {
"type" : "long"
},
"serve_type_name" : {
"type" : "text",
"index" : false
},
"total_amount" : {
"type" : "double"
}
}
}
}创建serve_aggregation索引 (已经存在无法重复创建)
PUT /serve_aggregation
{
"mappings" : {
"properties" : {
"city_code" : {
"type" : "keyword"
},
"detail_img" : {
"type" : "text",
"index" : false
},
"hot_time_stamp" : {
"type" : "long"
},
"id" : {
"type" : "keyword"
},
"is_hot" : {
"type" : "short"
},
"price" : {
"type" : "double"
},
"serve_item_icon" : {
"type" : "text",
"index" : false
},
"serve_item_id" : {
"type" : "keyword"
},
"serve_item_img" : {
"type" : "text",
"index" : false
},
"serve_item_name" : {
"type" : "text",
"analyzer": "ik_max_word",
"search_analyzer":"ik_smart"
},
"serve_item_sort_num" : {
"type" : "short"
},
"serve_type_icon" : {
"type" : "text",
"index" : false
},
"serve_type_id" : {
"type" : "keyword"
},
"serve_type_img" : {
"type" : "text",
"index" : false
},
"serve_type_name" : {
"type" : "text",
"analyzer": "ik_max_word",
"search_analyzer":"ik_smart"
},
"serve_type_sort_num" : {
"type" : "short"
}
}
}
}