




向量检索和图检索,用哪个好呢?
本文最后更新于 2025-05-16,文章超过7天没更新,应该是已完结了~
向量检索是什么?
与传统的全文搜索(主要依赖于精确的关键词匹配和词频)不同,向量搜索通过将不同类型的数据(如文本、图像或音频)转换为高维向量,并根据这些向量之间的相似度来进行查询。这种搜索方法能够捕捉数据的语义特征和上下文信息,从而更准确地理解用户意图。
即使搜索的词语与数据库中的内容不完全匹配,向量搜索仍然可以通过对数据语义的理解,找到与用户意图相符合的结果。
例如,搜索 “一种会游泳的动物” 时,全文搜索只会返回包含这些精确关键词的结果,而向量搜索可以返回其他游泳动物的结果,如鱼或鸭子,即使这些结果并未包含精确的关键词。
图检索是什么?
图检索是一种基于图结构数据进行查询的检索方法,主要用于处理以节点(entities)和边(relationships)形式组织的数据。与传统的向量检索或全文检索不同,图检索关注的是实体之间的关系和结构化信息。它的核心目标是基于图的拓扑结构或属性查询信息。
RAG
大型语言模型(LLM)用海量数据进行训练,使用数十亿个参数为回答问题、翻译语言和完成句子等任务生成原始输出。在 LLM 本就强大的功能基础上,RAG 将其扩展为能访问特定领域或组织的内部知识库,所有这些都无需重新训练模型。
LLM 面临的已知挑战包括:
在没有答案的情况下提供虚假信息。
当用户需要特定的当前响应时,提供过时或通用的信息。
从非权威来源创建响应。
由于术语混淆,不同的培训来源使用相同的术语来谈论不同的事情,因此会产生不准确的响应。
您可以将大型语言模型看作是一个过于热情的新员工,他拒绝随时了解时事,但总是会绝对自信地回答每一个问题。不幸的是,这种态度会对用户的信任产生负面影响,这是您不希望聊天机器人效仿的!
RAG 是解决其中一些挑战的一种方法。它会重定向 LLM,从权威的、预先确定的知识来源中检索相关信息。组织可以更好地控制生成的文本输出,并且用户可以深入了解 LLM 如何生成响应。
应用场景
🔍 1. 开放域问答与知识检索
RAG 在开放域问答系统中表现出色,能够根据用户查询,从大规模知识库(如维基百科、企业文档)中检索相关信息,并生成准确的回答。例如,用户询问“2025 年有哪些重大科技突破?”,系统会检索最新的科技新闻或研究成果,提供实时且可靠的答案。
🧑💼 2. 客户服务与智能助手
在客户服务领域,RAG 被用于构建智能客服机器人和虚拟助手。这些系统能够实时访问产品手册、常见问题解答(FAQ)和用户历史记录,生成个性化的响应,提高客户满意度和支持效率。
🏢 3. 企业知识管理与内部搜索
RAG 技术被广泛应用于企业内部知识管理系统,帮助员工快速检索政策文件、操作手册和项目文档。例如,某房地产投资公司使用 RAG 自动标记文件,并组织成知识库,提升数据访问效率。
📚 4. 教育与学习辅助
在教育领域,RAG 可用于开发智能学习助手,为学生提供基于教材的精准解答,辅助教师生成教学内容。此外,RAG 还可用于自动生成练习题、摘要和学习指南,提升教学效率。
⚖️ 5. 法律与合规支持
法律专业人员利用 RAG 技术进行案例检索、法律条文查询和合同分析。通过从法律数据库中检索相关信息,RAG 系统能够生成初步的法律意见草案,辅助律师进行法律研究和文书撰写。
🧬 6. 医疗与科研信息整合
在医疗和科研领域,RAG 被用于整合和分析大量的研究文献、临床试验数据和医学指南。研究人员和医生可以通过 RAG 系统快速获取相关信息,支持临床决策和科研工作。
🖼️ 7. 多模态内容生成
RAG 技术正在扩展到多模态领域,结合文本、图像、音频等多种数据类型,提升生成内容的丰富性和准确性。例如,多模态 RAG 系统可以根据文本描述生成相应的图像说明,或在视觉问答中提供更准确的回答。
🧠 8. 复杂推理与知识图谱集成
Graph RAG(基于知识图谱的检索增强生成)结合了图结构数据,适用于需要复杂关系推理的任务,如多跳问答和实体关系分析。这种方法在医疗健康、科研综述和企业知识管理等领域具有独特优势。
🧾 9. 内容创作与自动化写作
内容创作者利用 RAG 技术进行文章撰写、摘要生成和信息整合。通过从多个信息源中检索相关内容,RAG 系统能够生成结构清晰、信息丰富的文本,辅助新闻报道、市场分析和报告撰写。
📊 10. 数据分析与报告生成
在数据分析领域,RAG 被用于自动生成数据报告和洞察分析。系统可以根据用户查询,从数据库中检索相关数据,生成可视化报告和分析摘要,提升决策效率。
VectorRAG
工作原理
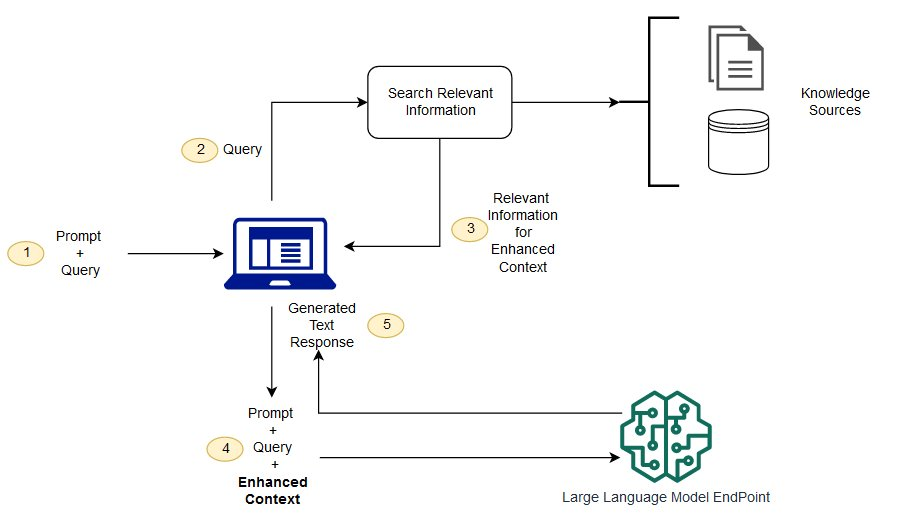
创建外部数据:LLM 原始训练数据集之外的新数据称为外部数据。它可以来自多个数据来源,例如 API、数据库或文档存储库。数据可能以各种格式存在,例如文件、数据库记录或长篇文本。另一种称为嵌入语言模型的 AI 技术将数据转换为数字表示形式并将其存储在向量数据库中。这个过程会创建一个生成式人工智能模型可以理解的知识库。
检索相关信息:下一步是执行相关性搜索。用户查询将转换为向量表示形式,并与向量数据库匹配。例如,考虑一个可以回答组织的人力资源问题的智能聊天机器人。如果员工搜索:“我有多少年假?”,系统将检索年假政策文件以及员工个人过去的休假记录。这些特定文件将被退回,因为它们与员工输入的内容高度相关。相关性是使用数学向量计算和表示法计算和建立的。
增强 LLM 提示:接下来,RAG 模型通过在上下文中添加检索到的相关数据来增强用户输入(或提示)。通俗点来说,就是我们给 LLM加一段检索结果的数据作为回答依据,然后再结合 用户的提问,回答问题。
更新外部数据:下一个问题可能是——如果外部数据过时了怎么办? 要维护当前信息以供检索,请异步更新文档并更新文档的嵌入表示形式。您可以通过自动化实时流程或定期批处理来执行此操作。
缺点
1. 缺乏结构化关系理解,多跳推理能力有限
RAG 主要依赖向量相似度进行检索,处理的是非结构化文本数据,难以捕捉实体之间的复杂关系,比如要问客户A和客户B的关系,文档中没有明确说明如“客户A和客户B是合作关系”,而是类似“客户A和客户C是合作关系,客户C和客户B是合作关系”,那么 检索结果只会返回客户 A和客户B相关文档,而不会分清楚其 之间关系。
2. 上下文理解能力较弱
由于 RAG 处理的是分散的文本块,缺乏对整体上下文的理解,可能导致生成的答案缺乏连贯性和准确性。比如 用户提问:“孙悟空 技能有哪些”,它可能会返回除了孙悟空的技能,还会返回猪八戒的技能。
GraphRAG
知识图谱,是结构化的语义知识库,用于迅速描述物理世界中的概念及其相互关系,通过知识图谱能够将Web上的信息、数据以及链接关系聚集为知识,使信息资源更易于计算、理解以及评价,并能实现知识的快速响应和推理。
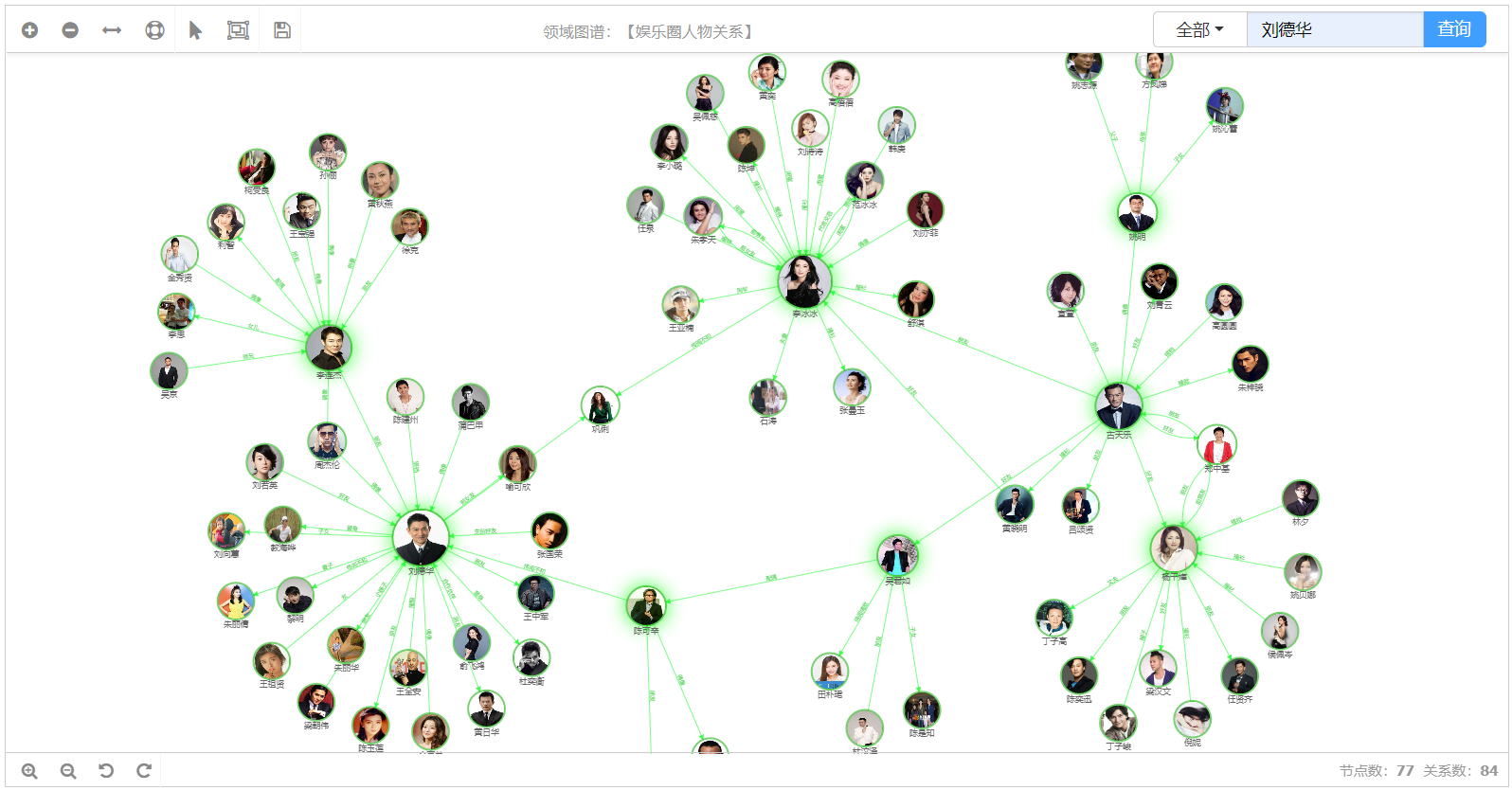
知识图谱的具体搭建过程及概念,可以 参考这篇文章:
GraphRAG 是在传统 RAG(Retrieval-Augmented Generation)基础上,融合知识图谱的一种增强型检索生成框架。
GraphRAG 过程包括从原始文本中提取出知识图谱,构建社区层级(这种结构通常用来描述个体、群体及它们之间的关系,帮助理解信息如何在社区内部传播、知识如何共享以及权力和影响力如何分布),为这些社区层级生成摘要,然后在执行基于 RAG 的任务时利用这些结构。
GraphRAG使用案例,可以 参考这篇文章:
对这篇文章,要补充一些东西:
graphrag 提供了两种检索方式,局部检索 和 全局检索,两种方式的检索效果是不一样的。
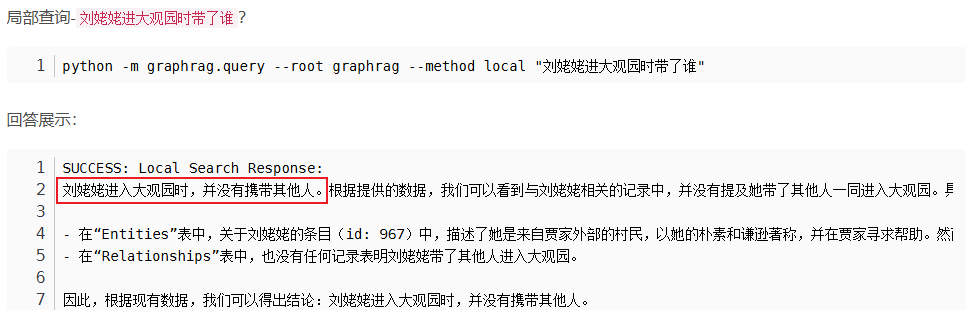

怎么理解这两种检索方式的区别呢?
1. 局部检索(Local Retrieval)——“聚焦实体的侦探”
当你要问一个“关于某个特定角色/事物”的问题时(例如“洋甘菊有哪些治疗特性?”),GraphRAG 会先在知识图谱里“锁定”这个实体(洋甘菊),然后:从图里提取和它直接相关的节点和关系(比如“成分→功效”、“历史用法→适应症”),聚焦的是实体本身。
2. 全局检索(Global Retrieval)——“浏览全图的向导”
当你问的是一个“宏观主题”或“跨实体话题”的问题时(例如“当前有哪些主流的草本抗炎疗法?”),GraphRAG 会:
把整个私有数据集(所有图里所有实体)先按照语义“打包成若干主题簇”(比如“抗炎成分簇”、“药理机理簇”、“临床应用簇”),
用户一提问,就找到最相关的那几个簇(比如“抗炎成分簇”+“临床应用簇”),
用这些簇里的核心摘要(簇里最具代表性的句子或节点关系)来喂给大模型,让它能够从“整体”上总结出一份宏观报告。主题簇可以理解为图上的实体为相关提问的实体。
局部检索 用在“深入了解单个实体/节点”的场景,让回答更精准、有证据;
全局检索 用在“宏观主题总结/跨实体话题”的场景,让回答更全面、有条理。
两者结合,就能让 GraphRAG 既能“钻进微观细节”,也能“俯瞰全局大势”。
那么刚介绍了RAG,也阐述了其缺点,那么GraphRAG是怎么解这些问题呢 ?
知识的结构化表示:GraphRAG 使用图结构来表示知识,使得检索不仅仅局限于简单的文档,而是可以通过图中的节点和边直接获取相关的实体和关系。这种方式使得检索到的信息更加结构化和有意义。
信息整合能力增强:传统的 RAG 模型可能会面临如何整合检索到的信息的问题,而 GraphRAG 通过图结构的连接性和结构化特性,可以有效地整合不同节点的信息。模型可以从图中获取更为系统化和关联性强的知识,从而提高生成内容的准确性和连贯性。
优化生成过程:GraphRAG 通过图的结构化方式,有助于生成模型更好地理解数据的语义关系。生成过程可以更好地利用图中的实体和关系信息,从而使生成的内容更加精准和高效。
对于传统 RAG 模型受限的开发者或研究人员,GraphRAG 提供了一种新的思路:通过引入知识图谱和图结构来增强信息的检索和整合能力。这种方法可以帮助他们克服传统 RAG 模型的不足,尤其是在需要处理大量结构化知识和复杂关系的任务中。
那我们直接用GraphRAG就好了,还需要传统RAG(Vector)吗
GraphRAG的局限性需要VectorRAG补充
长尾/实时信息:GraphRAG的知识图谱更新有延迟,VectorRAG能即时检索非结构化文档(如邮件、新闻、报告)中的最新细节。
深度文本分析:情感分析、条款解读等任务需依赖原文,VectorRAG可直接检索相关段落供LLM生成综合判断。
开放式模糊问题:涉及行业动态预测等场景,需结合外部研究,VectorRAG能灵活检索分散的关联信息。
核心差异
GraphRAG基于结构化关系(如实体间的关联),适合回答依赖知识图谱的逻辑推理问题;而VectorRAG通过语义相似性匹配文本片段,更适合处理非结构化、实时或细粒度文本需求。协同价值
两者结合可覆盖更广场景:GraphRAG提供结构化知识框架,VectorRAG补充动态细节和原文分析,形成「框架+碎片」的完整解决方案。
Qdrant + Neo4j:GraphRAG 架构下双引擎协同的优势解析
在基于知识图谱的检索增强生成(GraphRAG)架构中,结合 Qdrant(向量检索) 和 Neo4j(图数据库) 的双引擎模式,能够显著提升系统的检索能力、推理深度及运行效率。这种协同设计不仅优化了传统 RAG 的局限性,还在复杂查询、上下文理解及成本控制等方面展现出独特优势。
1. 改进的召回率与精度
Qdrant 的向量检索 通过语义相似度匹配,扩展检索覆盖面,确保不遗漏潜在相关但表述不同的内容(如近义词、行业术语变体)。
Neo4j 的图结构 则基于实体间的显式关联(如“客户A→合作→客户B”)过滤噪声,提升结果的相关性与准确性。
协同效应:向量检索广撒网,图谱检索精准收束,二者结合实现高召回率与高精度的平衡。
2. 增强的上下文理解能力
Neo4j 的实体—关系建模 天然适合表达复杂逻辑(如供应链网络、股权结构),使系统能够基于多跳关系进行推理(例如:“客户A的竞争对手有哪些?”)。
Qdrant 的语义检索 补充图谱未覆盖的文本细节(如合同条款的模糊描述、新闻中的隐含关联),避免因图谱不完整导致的遗漏。
典型场景:在分析“客户投诉的根本原因”时,图谱提供事件链(订单→物流→反馈),向量检索则定位具体投诉文本中的关键词句。
3. 对复杂查询的强适应性
结构化查询(Neo4j):高效处理多跳、条件化的问题(如“找出近两年与客户A合作且行业为金融的所有供应商”)。
开放式查询(Qdrant):应对模糊或长尾需求(如“预测行业趋势”),通过向量搜索快速关联分散的行业报告、研究论文等内容。
动态互补:用户提问“客户B的技术优势”时,图谱返回其专利布局,向量检索补充其技术白皮书中的具体描述。
4. 成本优化与可扩展性
资源分工:向量检索承担非结构化文本的初步筛选,减少图遍历和 LLM 调用的计算负担。
轻量级增强:结合 NER(命名实体识别)等技术,部分替代 LLM 的实体抽取任务,进一步降低成本。
扩展灵活性:双引擎架构适应数据增长——Qdrant 支持高维向量的分布式检索,Neo4j 则优化了图的分布式存储与查询。
核心结论:双引擎协同的价值
通过 Qdrant + Neo4j 的协同设计,GraphRAG 系统实现了以下突破:
更全面的检索能力:同时覆盖语义相似性与逻辑关联性。
更深的推理层次:结合结构化关系与非结构化文本细节。
更高的性价比:通过分工降低 LLM 依赖,适应实时更新与大规模数据场景。
这种架构尤其适用于需兼顾 精准推理 与 语义泛化 的场景(如金融风控、智能客服、行业研究),为下一代 RAG 系统的设计提供了重要参考。
核心原理
Query Vectorization: An embedding model converts The user query into a high-dimensional vector.
查询矢量化: 嵌入模型将 The user 查询转换为高维向量。Semantic Search: The vector performs a similarity-based search in the Vector database, retrieving relevant documents or entries.
语义搜索: 向量在 Vector 数据库中执行基于相似性的搜索,检索相关文档或条目。ID Extraction: Extracted IDs from the semantic search results are used to query the Graph database.
ID 提取: 从语义搜索结果中提取的 ID 用于查询 Graph 数据库 。Graph Context Retrieval: The Graph database provides contextual information, including relationships and entities linked to the extracted IDs.
图上下文检索:Graph 数据库提供上下文信息,包括链接到提取的 ID 的关系和实体。Response Generation: The context retrieved from the graph is passed to an LLM to generate a final response.
响应生成: 从图形中检索到的上下文将传递给 LLM 以生成最终响应。Results: The generated response is returned to the user.
结果: 生成的响应将返回给用户。
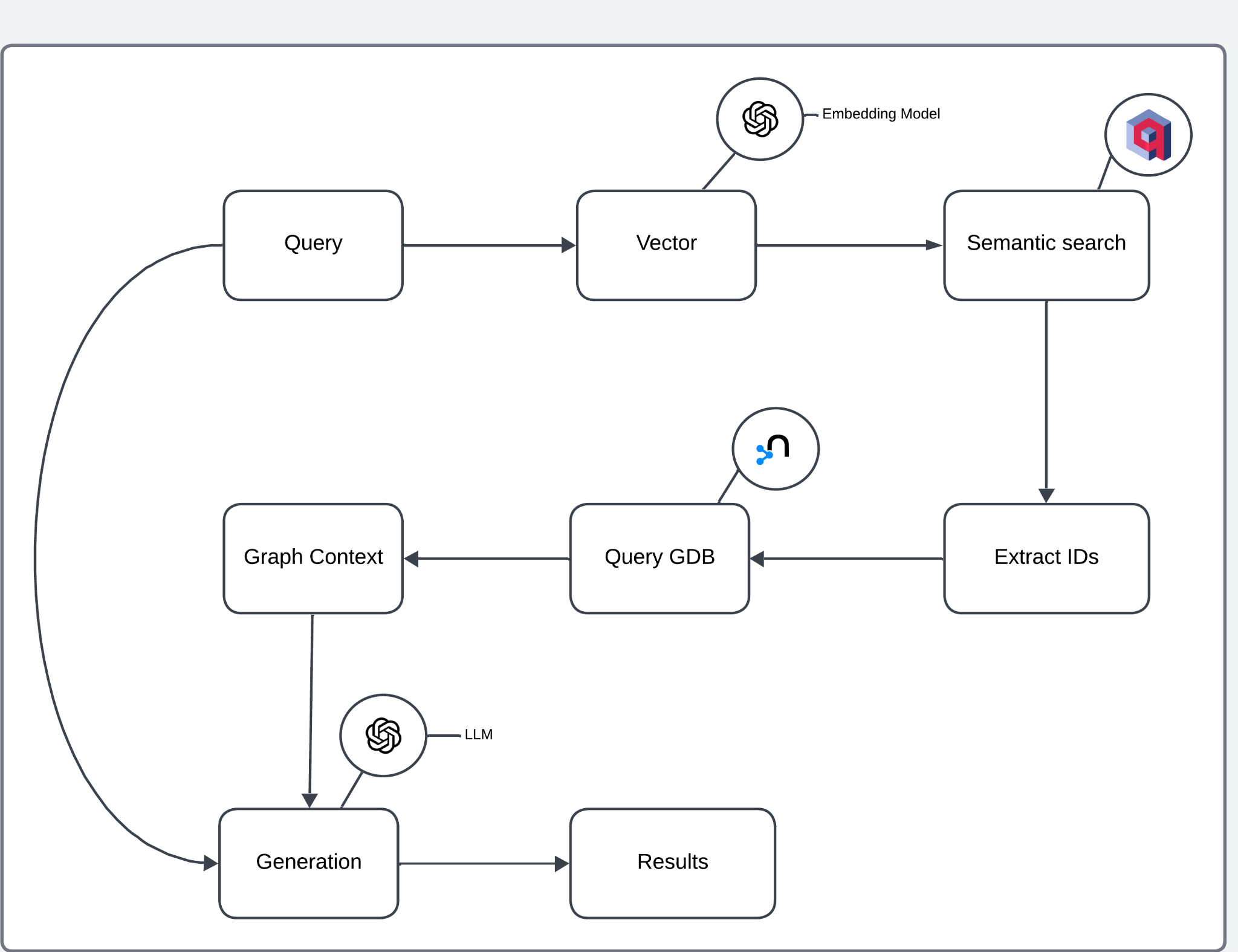
此体系结构结合了两个数据库的优势:
Semantic Search with Vector Database: The user query is first processed semantically to identify the most relevant data points without needing explicit keyword matches.
使用 Vector Database 进行语义搜索: 首先对用户查询进行语义处理,以识别最相关的数据点,而无需明确的关键字匹配。Contextual Expansion with Graph Database: IDs or entities retrieved from the vector database query the graph database for detailed relationships, enriching the retrieved data with structured context.
使用图形数据库进行上下文扩展: 从矢量数据库中检索到的 ID 或实体会查询图形数据库以获取详细关系,从而使用结构化上下文丰富检索到的数据。Enhanced Generation: The architecture combines semantic relevance (from the vector database) and graph-based context to enable the LLM to generate more informed, accurate, and contextually rich responses.
增强生成: 该架构结合了语义相关性(来自向量数据库)和基于图形的上下文,使 LLM 能够生成更明智、更准确和上下文更丰富的响应。
