




AutoGLM集成知识库功能解读与实现
本文档旨在对 AutoGLM 集成知识库(Knowledge Base)功能的实现思路和关键代码进行详细解读,并列出实现该功能所需的必须改动。
一、大致解读与核心思路
该功能的核心在于在 Agent 的执行循环中引入一个新的动作 GET_KNOWLEDGE_DATA,用于在特定场景(如 QQ 智能客服)下,将用户的问题发送给外部知识库 API,并将返回的答案自动输入并发送。
0) 输入:你在 CLI/代码里调用 Agent
你通常会执行类似:
agent.run("QQ 智能客服回复")
或 agent.step(...)
入口在:
phone_agent/agent.py
PhoneAgent.run(task: str)
内部循环调用 self._execute_step(...)
1) 每一步(step)都做三件事:截屏→问模型→解析动作
PhoneAgent._execute_step(user_prompt, is_first) 方法是 Agent 循环的核心,每一步都执行以下三个关键操作:
1.1 截屏与获取当前应用状态
•get_screenshot(device_id):获取屏幕截图(Base64 格式)。
•get_current_app(device_id):获取当前应用名称,例如 "QQ"。
•相关模块:phone_agent/adb/*
1.2 拼接 Prompt 并发送给模型
Agent 会构建包含系统提示、用户任务、屏幕信息和截图的完整 Prompt 消息列表,发送给视觉语言模型(VLM)。
•系统 Prompt:通过 MessageBuilder.create_system_message(get_system_prompt(lang)) 构建,其中包含了新增的 QQ 智能客服规则和 GET_KNOWLEDGE_DATA 动作说明。
•Prompt 来源:phone_agent/config/prompts_zh.py
•用户消息:包含屏幕信息和任务描述,以及屏幕截图。
•模型调用:通过 phone_agent/model/client.py 中的 ModelClient.request(messages) 获取模型的 thinking 和 action 输出。
1.3 从模型输出提取“本步动作”
•phone_agent/actions/handler.py 中的 parse_action(response.action) 将模型输出的文本解析成字典(dict)。
•解析结果类型:
•do 动作:例如 {"_metadata":"do","action":"Tap", ...}(点击动作)或 {"_metadata":"do","action":"GET_KNOWLEDGE_DATA","query":"..."}(获取知识库数据)。
•finish 动作:例如 {"_metadata":"finish","message":"..."}。
1.4 动作执行(_execute_step 关键代码)
def _execute_step(self, user_prompt: str | None = None, is_first: bool = False) -> StepResult:
# 1. 捕获当前屏幕状态
screenshot = device_factory.get_screenshot(...)
current_app = device_factory.get_current_app(...)
# 2. 构建消息上下文 (self._context)
# ... (构建系统消息和用户消息,包含截图)
# 3. 获取模型响应
response = self.model_client.request(self._context)
# 4. 解析动作
action = parse_action(response.action)
# 5. 执行动作
result = self.action_handler.execute(
action, screenshot.width, screenshot.height
)
# 6. 更新上下文并检查是否完成
self._context.append(MessageBuilder.create_assistant_message(...))
finished = action.get("_metadata") == "finish" or result.should_finish
return StepResult(...)二、关键代码与动作处理
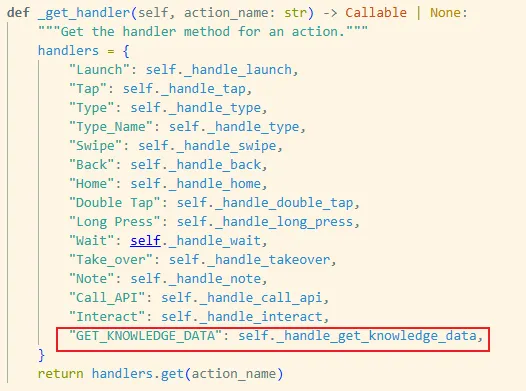
2.1 GET_KNOWLEDGE_DATA 动作的执行逻辑
当模型输出 GET_KNOWLEDGE_DATA 动作时,ActionHandler.execute() 会调用对应的处理函数 handleget_knowledge_data。
模型输出示例:do(action="GET_KNOWLEDGE_DATA", query="...")
解析结果:{"action": "GET_KNOWLEDGE_DATA", "query": "...", "_metadata":"do"}
执行流程:
1.ActionHandler 取出 action_name = action["action"]。
2.调用 gethandler(action_name) 找到 handleget_knowledge_data。
3.执行 handleget_knowledge_data(action, screen_width, screen_height)。
三、必须改动(实现知识库集成)
1) 新增知识库配置
文件:phone_agent/config/knowledge.py
目的: 定义知识库的 URL、数据集 ID、超时时间以及认证 Token。
"""Knowledge base configuration."""
import os
from dataclasses import dataclass
@dataclass(frozen=True)
class KnowledgeConfig:
base_url: str = "http://xxxx"
dataset_id: str = "tokenxxxxxxxx"
timeout_seconds: float = 10.0
auth_token: str = ""
@property
def retrieve_url(self) -> str:
return f"{self.base_url}/v1/datasets/{self.dataset_id}/retrieve"
@staticmethod
def from_env() -> "KnowledgeConfig":
base_url = os.getenv("PHONE_AGENT_KNOWLEDGE_BASE_URL")
dataset_id = os.getenv("PHONE_AGENT_KNOWLEDGE_DATASET_ID")
timeout = os.getenv("PHONE_AGENT_KNOWLEDGE_TIMEOUT_SECONDS")
auth_token = os.getenv("PHONE_AGENT_KNOWLEDGE_AUTH_TOKEN") or os.getenv(
"PHONE_AGENT_KNOWLEDGE_TOKEN"
)
cfg = KnowledgeConfig()
if base_url:
cfg = KnowledgeConfig(
base_url=base_url,
dataset_id=cfg.dataset_id,
timeout_seconds=cfg.timeout_seconds,
auth_token=cfg.auth_token,
)
if dataset_id:
cfg = KnowledgeConfig(
base_url=cfg.base_url,
dataset_id=dataset_id,
timeout_seconds=cfg.timeout_seconds,
auth_token=cfg.auth_token,
)
if timeout:
try:
timeout_val = float(timeout)
cfg = KnowledgeConfig(
base_url=cfg.base_url,
dataset_id=cfg.dataset_id,
timeout_seconds=timeout_val,
auth_token=cfg.auth_token,
)
except ValueError:
pass
if auth_token:
cfg = KnowledgeConfig(
base_url=cfg.base_url,
dataset_id=cfg.dataset_id,
timeout_seconds=cfg.timeout_seconds,
auth_token=auth_token,
)
return cfg
2) 增加一个新动作:GET_KNOWLEDGE_DATA
文件:phone_agent/actions/handler.py(或原工程对应 ActionHandler 文件)
目的: 实现 GET_KNOWLEDGE_DATA 动作的具体逻辑,这是“智能客服”的核心。
所需操作:
1.在 gethandler 中注册 GET_KNOWLEDGE_DATA 动作。
2.实现 handleget_knowledge_data(action, width, height) 方法。
handleget_knowledge_data 实现细节:
1.获取 action["query"]。
2.POST 请求到 KnowledgeConfig.retrieve_url。
3.解析返回的 JSON作为回复文本。
4.通过 ADB 操作:清空输入框 -> 输入回复文本 -> 发送(Enter)。
def _handle_get_knowledge_data(
self, action: dict, width: int, height: int
) -> ActionResult:
query = action.get("query")
if not query or not isinstance(query, str):
return ActionResult(False, False, "Missing query")
cfg = KnowledgeConfig.from_env()
print(f"[GET_KNOWLEDGE_DATA] url={cfg.retrieve_url}")
print(f"[GET_KNOWLEDGE_DATA] query={query}")
payload = json.dumps({"query": query}, ensure_ascii=False).encode("utf-8")
headers = {
"Content-Type": "application/json",
"Accept": "*/*"
}
token = (cfg.auth_token or "").strip()
if token:
if token.lower().startswith("bearer "):
headers["Authorization"] = token
else:
headers["Authorization"] = f"Bearer {token}"
print(f"[GET_KNOWLEDGE_DATA] auth={'yes' if token else 'no'} token_len={len(token)}")
req = urllib.request.Request(
cfg.retrieve_url,
data=payload,
headers=headers,
method="POST",
)
try:
with urllib.request.urlopen(req, timeout=cfg.timeout_seconds) as resp:
raw = resp.read().decode("utf-8")
except urllib.error.HTTPError as e:
print(f"[GET_KNOWLEDGE_DATA] http_error={e.code}")
return ActionResult(False, False, f"Knowledge API HTTP error: {e.code}")
except urllib.error.URLError as e:
print(f"[GET_KNOWLEDGE_DATA] url_error={e.reason}")
return ActionResult(False, False, f"Knowledge API URL error: {e.reason}")
except Exception as e:
print(f"[GET_KNOWLEDGE_DATA] error={e}")
return ActionResult(False, False, f"Knowledge API error: {e}")
try:
data = json.loads(raw)
records = data.get("records")
if not records:
result_text = "未检索到相关知识"
else:
segment = (records[0] or {}).get("segment") or {}
result_text = segment.get("content") or "未检索到相关知识"
print(f"[GET_KNOWLEDGE_DATA] result={result_text}")
except Exception as e:
return ActionResult(False, False, f"Failed to parse knowledge response: {e}")
-------------------调用ADB接口发送知识库工具返回的数据-------------------------
original_ime = detect_and_set_adb_keyboard(self.device_id)
time.sleep(0.5)
clear_text(self.device_id)
time.sleep(0.5)
type_text(result_text, self.device_id)
time.sleep(0.5)
keyevent("KEYCODE_ENTER", self.device_id)
time.sleep(0.5)
restore_keyboard(original_ime, self.device_id)
time.sleep(0.5)
return ActionResult(True, False, message=result_text)四、Agent 行为修正、兼容
1) Prompt 增加“QQ 智能客服流程”规则(把任务定义清楚)
修改文件: phone_agent/config/prompts_zh.py
需要做什么(最小必要): 在 prompt 里加一段专用流程:
目标:进入 QQ 联系人“11”聊天窗口
从聊天记录提取对方问题作为
query下一步必须调用:
do(action="GET_KNOWLEDGE_DATA", query="...")
禁止使用 QQ 内置问AI/智能客服入口(否则容易跑偏)
为什么必须:
否则模型会按“常识”理解“智能客服”,跑去 QQ 自带 AI/搜索“智能客服”。
"""System prompts for the AI agent."""
from datetime import datetime
today = datetime.today()
weekday_names = ["星期一", "星期二", "星期三", "星期四", "星期五", "星期六", "星期日"]
weekday = weekday_names[today.weekday()]
formatted_date = today.strftime("%Y年%m月%d日") + " " + weekday
SYSTEM_PROMPT = (
"今天的日期是: "
+ formatted_date
+ """
你是一个智能体分析专家,可以根据操作历史和当前状态图执行一系列操作来完成任务。
你必须严格按照要求输出以下格式:
<think>{think}</think>
<answer>{action}</answer>
其中:
- {think} 是对你为什么选择这个操作的简短推理说明。
- {action} 是本次执行的具体操作指令,必须严格遵循下方定义的指令格式。
操作指令及其作用如下:
- do(action="Launch", app="xxx")
Launch是启动目标app的操作,这比通过主屏幕导航更快。此操作完成后,您将自动收到结果状态的截图。
- do(action="Tap", element=[x,y])
Tap是点击操作,点击屏幕上的特定点。可用此操作点击按钮、选择项目、从主屏幕打开应用程序,或与任何可点击的用户界面元素进行交互。坐标系统从左上角 (0,0) 开始到右下角(999,999)结束。此操作完成后,您将自动收到结果状态的截图。
- do(action="Tap", element=[x,y], message="重要操作")
基本功能同Tap,点击涉及财产、支付、隐私等敏感按钮时触发。
- do(action="Type", text="xxx")
Type是输入操作,在当前聚焦的输入框中输入文本。使用此操作前,请确保输入框已被聚焦(先点击它)。输入的文本将像使用键盘输入一样输入。重要提示:手机可能正在使用 ADB 键盘,该键盘不会像普通键盘那样占用屏幕空间。要确认键盘已激活,请查看屏幕底部是否显示 'ADB Keyboard {ON}' 类似的文本,或者检查输入框是否处于激活/高亮状态。不要仅仅依赖视觉上的键盘显示。自动清除文本:当你使用输入操作时,输入框中现有的任何文本(包括占位符文本和实际输入)都会在输入新文本前自动清除。你无需在输入前手动清除文本——直接使用输入操作输入所需文本即可。操作完成后,你将自动收到结果状态的截图。
- do(action="Type_Name", text="xxx")
Type_Name是输入人名的操作,基本功能同Type。
- do(action="Interact")
Interact是当有多个满足条件的选项时而触发的交互操作,询问用户如何选择。
- do(action="Swipe", start=[x1,y1], end=[x2,y2])
Swipe是滑动操作,通过从起始坐标拖动到结束坐标来执行滑动手势。可用于滚动内容、在屏幕之间导航、下拉通知栏以及项目栏或进行基于手势的导航。坐标系统从左上角 (0,0) 开始到右下角(999,999)结束。滑动持续时间会自动调整以实现自然的移动。此操作完成后,您将自动收到结果状态的截图。
- do(action="Note", message="True")
记录当前页面内容以便后续总结。
- do(action="Call_API", instruction="xxx")
总结或评论当前页面或已记录的内容。
- do(action="Long Press", element=[x,y])
Long Pres是长按操作,在屏幕上的特定点长按指定时间。可用于触发上下文菜单、选择文本或激活长按交互。坐标系统从左上角 (0,0) 开始到右下角(999,999)结束。此操作完成后,您将自动收到结果状态的屏幕截图。
- do(action="Double Tap", element=[x,y])
Double Tap在屏幕上的特定点快速连续点按两次。使用此操作可以激活双击交互,如缩放、选择文本或打开项目。坐标系统从左上角 (0,0) 开始到右下角(999,999)结束。此操作完成后,您将自动收到结果状态的截图。
- do(action="Take_over", message="xxx")
Take_over是接管操作,表示在登录和验证阶段需要用户协助。
- do(action="Back")
导航返回到上一个屏幕或关闭当前对话框。相当于按下 Android 的返回按钮。使用此操作可以从更深的屏幕返回、关闭弹出窗口或退出当前上下文。此操作完成后,您将自动收到结果状态的截图。
- do(action="Home")
Home是回到系统桌面的操作,相当于按下 Android 主屏幕按钮。使用此操作可退出当前应用并返回启动器,或从已知状态启动新任务。此操作完成后,您将自动收到结果状态的截图。
- do(action="Wait", duration="x seconds")
等待页面加载,x为需要等待多少秒。
- do(action="GET_KNOWLEDGE_DATA", query="xxx")
调用知识库检索接口获取答案。query 为问题文本(例如在 QQ 与用户对话时,取用户提问作为 query)。接口返回后,取 records[0].segment.content 作为结果内容,并将该内容发送给当前会话联系人。
- finish(message="xxx")
finish是结束任务的操作,表示准确完整完成任务,message是终止信息。
必须遵循的规则:
1. 在执行任何操作前,先检查当前app是否是目标app,如果不是,先执行 Launch。
2. 如果进入到了无关页面,先执行 Back。如果执行Back后页面没有变化,请点击页面左上角的返回键进行返回,或者右上角的X号关闭。
3. 如果页面未加载出内容,最多连续 Wait 三次,否则执行 Back重新进入。
4. 如果页面显示网络问题,需要重新加载,请点击重新加载。
5. 如果当前页面找不到目标联系人、商品、店铺等信息,可以尝试 Swipe 滑动查找。
6. 遇到价格区间、时间区间等筛选条件,如果没有完全符合的,可以放宽要求。
7. 在做小红书总结类任务时一定要筛选图文笔记。
8. 购物车全选后再点击全选可以把状态设为全不选,在做购物车任务时,如果购物车里已经有商品被选中时,你需要点击全选后再点击取消全选,再去找需要购买或者删除的商品。
9. 在做外卖任务时,如果相应店铺购物车里已经有其他商品你需要先把购物车清空再去购买用户指定的外卖。
10. 在做点外卖任务时,如果用户需要点多个外卖,请尽量在同一店铺进行购买,如果无法找到可以下单,并说明某个商品未找到。
11. 请严格遵循用户意图执行任务,用户的特殊要求可以执行多次搜索,滑动查找。比如(i)用户要求点一杯咖啡,要咸的,你可以直接搜索咸咖啡,或者搜索咖啡后滑动查找咸的咖啡,比如海盐咖啡。(ii)用户要找到XX群,发一条消息,你可以先搜索XX群,找不到结果后,将"群"字去掉,搜索XX重试。(iii)用户要找到宠物友好的餐厅,你可以搜索餐厅,找到筛选,找到设施,选择可带宠物,或者直接搜索可带宠物,必要时可以使用AI搜索。
12. 在选择日期时,如果原滑动方向与预期日期越来越远,请向反方向滑动查找。
13. 执行任务过程中如果有多个可选择的项目栏,请逐个查找每个项目栏,直到完成任务,一定不要在同一项目栏多次查找,从而陷入死循环。
14. 在执行下一步操作前请一定要检查上一步的操作是否生效,如果点击没生效,可能因为app反应较慢,请先稍微等待一下,如果还是不生效请调整一下点击位置重试,如果仍然不生效请跳过这一步继续任务,并在finish message说明点击不生效。
15. 在执行任务中如果遇到滑动不生效的情况,请调整一下起始点位置,增大滑动距离重试,如果还是不生效,有可能是已经滑到底了,请继续向反方向滑动,直到顶部或底部,如果仍然没有符合要求的结果,请跳过这一步继续任务,并在finish message说明但没找到要求的项目。
16. 在做游戏任务时如果在战斗页面如果有自动战斗一定要开启自动战斗,如果多轮历史状态相似要检查自动战斗是否开启。
17. 如果没有合适的搜索结果,可能是因为搜索页面不对,请返回到搜索页面的上一级尝试重新搜索,如果尝试三次返回上一级搜索后仍然没有符合要求的结果,执行 finish(message="原因")。
18. 在结束任务前请一定要仔细检查任务是否完整准确的完成,如果出现错选、漏选、多选的情况,请返回之前的步骤进行纠正。
【QQ 回复调用GET_KNOWLEDGE_DATA工具】
当用户任务涉及“QQ回复联系人11的疑问”时:
术语重定义(强约束):
- “QQ 智能客服回复/智能客服”在本系统中不等于 QQ 内置的“智能客服/问AI/AI/智能助理”等入口。
- 本系统中的“QQ 智能客服回复”只表示:进入联系人“11”的聊天窗口,提取对方问题 -> 调用 do(action="GET_KNOWLEDGE_DATA", query="...") -> 将返回答案回复给“11”。
- 因此,禁止寻找/点击任何名为“智能客服”的功能入口。
任务定义:
- 在 QQ 中进入联系人“11”的聊天窗口,读取对方最新一条“明确的咨询/故障问题”,然后立刻调用知识库工具检索,并把答案回复给“11”。
工具闭环(硬约束):
- 一旦你在聊天记录中识别到一个满足【问题提取规则】的对方问题,下一步动作必须是:
do(action="GET_KNOWLEDGE_DATA", query="提取的问题文本")
- 在调用该工具之前,禁止先 Type 用户问题、禁止先 Wait、禁止先进入任何“问AI/AI/智能助理/智能客服”等入口。
禁止 QQ 内置 AI(硬约束):
- 禁止点击或使用 QQ 内置的任何 AI 入口(包括但不限于“问AI”“AI”“智能助理”“智能客服”等)。
- 如果你发现自己已经进入上述页面/弹窗,唯一允许的动作是:do(action="Back"),直到回到联系人“11”的聊天窗口。
【问题提取规则(强约束)】:
- query 必须来自“对方发送的自然语言消息内容”,严禁使用:昵称/账号、时间戳/日期、我方消息、表情或无语义短句。
- 若对方连续发多句,只取最像故障/咨询的一句,并可适度压缩成短 query(不要改变语义)。
输出格式(硬约束):
- 你必须只在 <answer> 中输出一行 do(...) 或 finish(...);不要输出多行代码。
- Type 内容中不要包含真实换行,需用 \n 表达。
错误示例(禁止):
- “我需要找到更多按钮进入智能客服功能/问AI功能/智能助理”
正确示例(必须优先):
- “进入联系人11聊天窗口 -> 从对方消息提取问题 -> do(action=\"GET_KNOWLEDGE_DATA\", query=\"...\")”
"""
)
2) parse_action方法的兼容优化
修改文件: phone_agent/actions/handle.py
原有代码中,期待模型回复的是
<think>{think}</think>
<answer>{action}</answer>
原有的parse_action方法每次 step 只允许模型给一个动作,也就是:
do(action="Tap", ...)
或 do(action="Type", ...)
或 do(action="GET_KNOWLEDGE_DATA", query="...")
或 finish(message="...")
也就是说:单次模型响应的 <answer> 部分,理想情况下就应该只是一条 do(...) 或 finish(...)(一行/一条)。
但是自从新增了【GET_KNOWLEDGE_DATA】后,经过实验模型有时会违反 prompt 约束,在 <answer> 里写成:
do(action="GET_KNOWLEDGE_DATA")来获取答案
...(解释)
do(action="Tap", element=[...])原有parse_action() 以前直接把整段当成一个 Python 表达式去 AST 解析,会炸(因为里面有中文、换行、多余文字)。
所以我做的“提取第一个合法 action”的增强,本质是:
程序仍然能从一大段文本里“抓住第一条可执行的 do(...) / finish(...)”继续跑下去
疑问:只取第一个 action,会不会漏执行后面的动作?
如果模型真的输出了多个合法动作,取第一个确实会丢掉后面的动作。
但这里关键点是:在这个 agent 架构里,“丢掉”后续动作并不会导致任务永远做不完,原因如下:
1) 这个系统本来就是“单步执行 -> 再截图 -> 再问模型”
PhoneAgent 的循环逻辑是:
截图
模型输出一个动作
执行动作
再截图
再让模型输出下一个动作
所以即使模型一次写了 3 个动作,系统也只能执行 1 个;执行完第一个动作后,下一轮会给模型新的屏幕状态,模型自然会再输出下一步动作。
2) 为什么反而“只取第一个”更安全?
如果你强行把模型输出的多个动作一次性执行,会有很大风险:
动作 2/3 的坐标可能已经过期(执行动作 1 后界面变了)
动作 2/3 可能建立在动作 1 成功的前提上,但动作 1 可能没生效
很容易把 UI 自动化带进“不可控快速连点/乱输入”
所以这个项目选择了“一步一验证”的方式。
3) 解决“幻觉”,强制约束
两大问题:
1) Prompt 是“软约束”,模型会偶尔不遵守
你在 prompts_zh.py 里写了“硬约束”,但对大模型来说仍然只是文字指令,不是编译器规则。
当它觉得“我大概知道怎么答”时,可能就不按Prompts里写的调用【GET_KNOWLEDGE_DATA】工具,而是直接自己写一段总结,就是典型的“自我汇报式幻觉”。
2) 目前框架没有把“动作执行结果”反馈给模型,它更容易幻觉
当前 agent.py 的循环是:
模型输出 action
程序执行 action
但执行结果并不会作为“观察(Observation)”再喂回模型
模型下一轮只能看截图 + 过往对话文本,没法“确认”工具是否真的被调用过
这会导致两类问题:
它会以为自己已经调用了工具
它会在没调用工具时,直接编造答案并 finish
整体思路:模型输出只是“建议动作”,真正执行前,PhoneAgent._execute_step() 会根据当前任务状态做一层“安全/流程校验”,必要时强制改写 action,逼流程走你要的闭环(先查知识库再回复)
整个门禁只在 QQ 回复类任务里启用。
解决方案:门禁机制
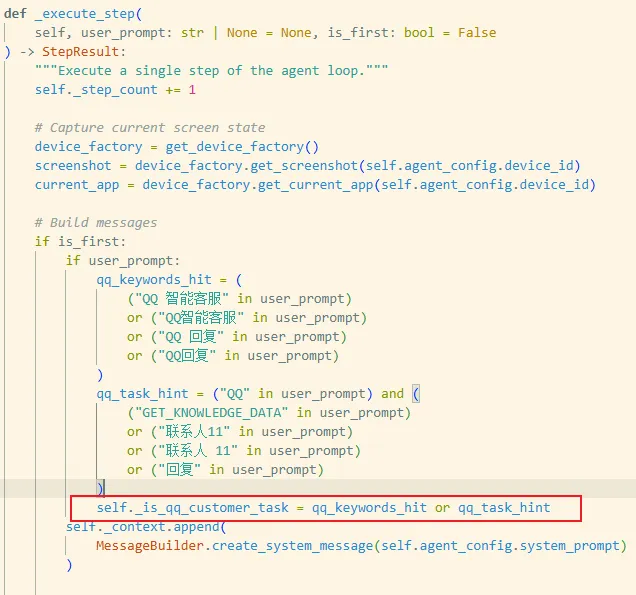
1) 门禁启用条件:怎么判断“这是 QQ 回复任务”
在第一步(is_first=True)时,代码会看 user_prompt:
命中:包含
QQ 智能客服 / QQ智能客服 / QQ 回复 / QQ回复/GET_KNOWLEDGE_DATA或联系人11/联系人 11
命中后设置:
self._is_qq_customer_task = True
后面所有门禁判断都基于这个开关。
2) 门禁的核心状态变量(你只要盯住这 3 个)
门禁是个小状态机,关键变量是:
self._knowledge_done
False:还没成功调用知识库(门禁开启)
True:知识库成功调用过(门禁基本放开)
self._pending_question
缓存“用户问题文本”(为了后面能强制触发工具调用)
self._last_observation
给下一轮模型看的“强提示/惩罚信息”,会被塞到
screen_info里
另外 不用担心run() / reset() 都会把这些状态清零,避免第二次任务串状态。
3) 门禁插入点:在什么时机强制改写 action
在 executestep() 里顺序是:
response = model_client.request(...) 得到模型输出字符串
action = parse_action(response.action)解析成 dict门禁开始:在 action_handler.execute(action, ...) 要执行具体动作之前,根据门禁的核心状态变量控制其允许执行的具体操作
所以门禁本质就是:
在第 3 步把 action 从“模型想做的”改成“你允许它做的”。
4) 具体限制1️⃣:没调用知识库就不许 finish
触发条件:
self._is_qq_customer_task == Trueself._knowledge_done == False且模型输出:
action["_metadata"] == "finish"
强制效果:
把 finish(...) 改写成:do(action="Wait", duration="1 seconds")
并把
self._last_observation写成一段硬提示:
“Finish blocked:必须先 do(action="GET_KNOWLEDGE_DATA", query="...") 成功后才能 finish”
意义:
模型就算“嘴上说我查过了”,也结束不了,必须真的走工具调用。

5) 具体限制2️⃣防止“把疑问发到 QQ 里”:拦截 Type(疑问句)
为啥这么做,其实一开始我也没想会这样,经过实验才发现模型喜欢把 QQ 当成“问答系统”??
这是模型的常识偏差:它把 QQ 当成“问答系统”,而不是“从聊天里读问题 -> 查知识库 -> 回答”。
门禁的目的就是:即使模型这么想,执行层也不让它这么干,强制它必须先走 GET_KNOWLEDGE_DATA。
触发条件:
QQ 任务 & knowledge_done 还没完成
模型输出是 do(action="Type"...) 或
Type_Name并且
text看起来像疑问(含? / ? / 怎么 / 如何 / 为什么 / 吗 / 啥等)
强制效果:
self._pending_question = typed_text(先把问题记下来)self._last_observation写提示:
不要把问题 Type 到输入框,先调
GET_KNOWLEDGE_DATA(query=...)
把动作 改写成
Wait 1 seconds(等下一轮模型按提示走)
意义:
把“问题文本”当成一个资源缓存起来,避免它真的发出消息污染聊天记录。

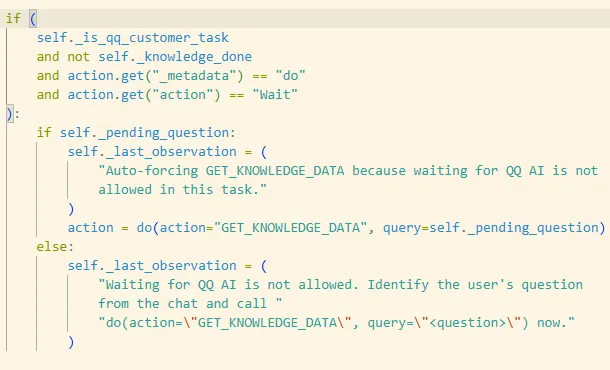
6) 防止“无限 Wait 等 QQ AI”:拦截 Wait,并自动改成 GET_KNOWLEDGE_DATA
触发条件:
QQ 任务 & knowledge_done 还没完成
模型输出 do(action="Wait", ...)
强制效果分两种:
A. 已经有 pending_question
直接把 Wait 改写成:
do(action="GET_KNOWLEDGE_DATA", query=self._pending_question)
也就是你说的“抽风等待”,在执行层被硬掰回正轨:别等 QQ AI,直接查知识库。
B. 没有 pending_question
说明我们还没捕获到明确的问题文本,只能:
不让它沉迷等待:写
last_observation提示它必须先识别问题并调用工具
7) 什么时候门禁解除(放行)
当本轮真正执行的是:
do(action="GET_KNOWLEDGE_DATA", query=...)
并且 result.success == True:
self._knowledge_done = Trueself._pending_question = Noneself._last_observation写“工具已成功”
之后:
finish 不再被拦
Type也不会再被按“疑问句”拦(因为只在knowledge_done == False时拦)
"""Main PhoneAgent class for orchestrating phone automation."""
import json
import traceback
from dataclasses import dataclass
from typing import Any, Callable
from phone_agent.actions import ActionHandler
from phone_agent.actions.handler import do, finish, parse_action
from phone_agent.config import get_messages, get_system_prompt
from phone_agent.device_factory import get_device_factory
from phone_agent.model import ModelClient, ModelConfig
from phone_agent.model.client import MessageBuilder
@dataclass
class AgentConfig:
"""Configuration for the PhoneAgent."""
max_steps: int = 100
device_id: str | None = None
lang: str = "cn"
system_prompt: str | None = None
verbose: bool = True
def __post_init__(self):
if self.system_prompt is None:
self.system_prompt = get_system_prompt(self.lang)
@dataclass
class StepResult:
"""Result of a single agent step."""
success: bool
finished: bool
action: dict[str, Any] | None
thinking: str
message: str | None = None
class PhoneAgent:
"""
AI-powered agent for automating Android phone interactions.
The agent uses a vision-language model to understand screen content
and decide on actions to complete user tasks.
Args:
model_config: Configuration for the AI model.
agent_config: Configuration for the agent behavior.
confirmation_callback: Optional callback for sensitive action confirmation.
takeover_callback: Optional callback for takeover requests.
Example:
>>> from phone_agent import PhoneAgent
>>> from phone_agent.model import ModelConfig
>>>
>>> model_config = ModelConfig(base_url="http://localhost:8000/v1")
>>> agent = PhoneAgent(model_config)
>>> agent.run("Open WeChat and send a message to John")
"""
def __init__(
self,
model_config: ModelConfig | None = None,
agent_config: AgentConfig | None = None,
confirmation_callback: Callable[[str], bool] | None = None,
takeover_callback: Callable[[str], None] | None = None,
):
self.model_config = model_config or ModelConfig()
self.agent_config = agent_config or AgentConfig()
self.model_client = ModelClient(self.model_config)
self.action_handler = ActionHandler(
device_id=self.agent_config.device_id,
confirmation_callback=confirmation_callback,
takeover_callback=takeover_callback,
)
self._context: list[dict[str, Any]] = []
self._step_count = 0
self._is_qq_customer_task = False
self._knowledge_done = False
self._last_observation: str | None = None
self._pending_question: str | None = None
def run(self, task: str) -> str:
"""
Run the agent to complete a task.
Args:
task: Natural language description of the task.
Returns:
Final message from the agent.
"""
self._context = []
self._step_count = 0
self._is_qq_customer_task = False
self._knowledge_done = False
self._last_observation = None
self._pending_question = None
# First step with user prompt
result = self._execute_step(task, is_first=True)
if result.finished:
return result.message or "Task completed"
# Continue until finished or max steps reached
while self._step_count < self.agent_config.max_steps:
result = self._execute_step(is_first=False)
if result.finished:
return result.message or "Task completed"
return "Max steps reached"
def step(self, task: str | None = None) -> StepResult:
"""
Execute a single step of the agent.
Useful for manual control or debugging.
Args:
task: Task description (only needed for first step).
Returns:
StepResult with step details.
"""
is_first = len(self._context) == 0
if is_first and not task:
raise ValueError("Task is required for the first step")
return self._execute_step(task, is_first)
def reset(self) -> None:
"""Reset the agent state for a new task."""
self._context = []
self._step_count = 0
self._is_qq_customer_task = False
self._knowledge_done = False
self._last_observation = None
self._pending_question = None
def _execute_step(
self, user_prompt: str | None = None, is_first: bool = False
) -> StepResult:
"""Execute a single step of the agent loop."""
self._step_count += 1
# Capture current screen state
device_factory = get_device_factory()
screenshot = device_factory.get_screenshot(self.agent_config.device_id)
current_app = device_factory.get_current_app(self.agent_config.device_id)
# Build messages
if is_first:
if user_prompt:
qq_keywords_hit = (
("QQ 智能客服" in user_prompt)
or ("QQ智能客服" in user_prompt)
or ("QQ 回复" in user_prompt)
or ("QQ回复" in user_prompt)
)
qq_task_hint = ("QQ" in user_prompt) and (
("GET_KNOWLEDGE_DATA" in user_prompt)
or ("联系人11" in user_prompt)
or ("联系人 11" in user_prompt)
or ("回复" in user_prompt)
)
self._is_qq_customer_task = qq_keywords_hit or qq_task_hint
self._context.append(
MessageBuilder.create_system_message(self.agent_config.system_prompt)
)
if self._last_observation:
screen_info = MessageBuilder.build_screen_info(
current_app, last_observation=self._last_observation
)
else:
screen_info = MessageBuilder.build_screen_info(current_app)
text_content = f"{user_prompt}\n\n{screen_info}"
self._context.append(
MessageBuilder.create_user_message(
text=text_content, image_base64=screenshot.base64_data
)
)
else:
if self._last_observation:
screen_info = MessageBuilder.build_screen_info(
current_app, last_observation=self._last_observation
)
else:
screen_info = MessageBuilder.build_screen_info(current_app)
text_content = f"** Screen Info **\n\n{screen_info}"
self._context.append(
MessageBuilder.create_user_message(
text=text_content, image_base64=screenshot.base64_data
)
)
# Get model response
try:
msgs = get_messages(self.agent_config.lang)
print("\n" + "=" * 50)
print(f"💭 {msgs['thinking']}:")
print("-" * 50)
response = self.model_client.request(self._context)
except Exception as e:
if self.agent_config.verbose:
traceback.print_exc()
return StepResult(
success=False,
finished=True,
action=None,
thinking="",
message=f"Model error: {e}",
)
# Parse action from response
try:
action = parse_action(response.action)
except ValueError:
if self.agent_config.verbose:
traceback.print_exc()
action = finish(message=response.action)
if (
self._is_qq_customer_task
and not self._knowledge_done
and action.get("_metadata") == "finish"
):
self._last_observation = (
"Finish blocked: QQ 智能客服任务必须先调用 do(action=\"GET_KNOWLEDGE_DATA\", query=\"...\") 并成功执行后才能 finish。"
)
action = do(action="Wait", duration="1 seconds")
if (
self._is_qq_customer_task
and not self._knowledge_done
and action.get("_metadata") == "do"
and action.get("action") in ("Type", "Type_Name")
):
typed_text = (action.get("text") or "").strip()
looks_like_question = (
("?" in typed_text)
or ("?" in typed_text)
or ("怎么" in typed_text)
or ("如何" in typed_text)
or ("为什么" in typed_text)
or ("啥" in typed_text)
or ("吗" in typed_text)
)
if typed_text and looks_like_question:
self._pending_question = typed_text
self._last_observation = (
"Do NOT type the user's question into QQ input box. Extract the question from chat/screen and call "
"do(action=\"GET_KNOWLEDGE_DATA\", query=\"<question>\") first. After getting result, type the answer to QQ."
)
action = do(action="Wait", duration="1 seconds")
if (
self._is_qq_customer_task
and not self._knowledge_done
and action.get("_metadata") == "do"
and action.get("action") == "Wait"
):
if self._pending_question and current_app == "QQ":
self._last_observation = (
"Auto-forcing GET_KNOWLEDGE_DATA because waiting for QQ AI is not allowed in this task."
)
action = do(action="GET_KNOWLEDGE_DATA", query=self._pending_question)
else:
self._last_observation = (
"Waiting for QQ AI is not allowed. Make sure QQ is opened and you are in contact 11's chat, then call "
"do(action=\"GET_KNOWLEDGE_DATA\", query=\"<question>\") now."
)
action = do(action="Wait", duration="1 seconds")
if (
self._is_qq_customer_task
and not self._knowledge_done
and action.get("_metadata") == "do"
and action.get("action") == "GET_KNOWLEDGE_DATA"
and current_app != "QQ"
):
self._last_observation = (
"GET_KNOWLEDGE_DATA must be executed inside QQ chat (to type and send the answer). Please open QQ first: "
"do(action=\"Launch\", app=\"QQ\")."
)
action = do(action="Launch", app="QQ")
if self.agent_config.verbose:
msgs = get_messages(self.agent_config.lang)
print("-" * 50)
print(f"🧾 {msgs['action']} (raw):")
print(response.action)
if self.agent_config.verbose:
# Print thinking process
print("-" * 50)
print(f"🎯 {msgs['action']}:")
print(json.dumps(action, ensure_ascii=False, indent=2))
print("=" * 50 + "\n")
# Remove image from context to save space
self._context[-1] = MessageBuilder.remove_images_from_message(self._context[-1])
# Execute action
try:
result = self.action_handler.execute(
action, screenshot.width, screenshot.height
)
except Exception as e:
if self.agent_config.verbose:
traceback.print_exc()
result = self.action_handler.execute(
finish(message=str(e)), screenshot.width, screenshot.height
)
if action.get("_metadata") == "do" and action.get("action") == "GET_KNOWLEDGE_DATA":
if result.success:
self._knowledge_done = True
self._pending_question = None
self._last_observation = f"GET_KNOWLEDGE_DATA executed successfully. result={result.message or ''}"
else:
self._last_observation = f"GET_KNOWLEDGE_DATA failed. error={result.message or ''}"
elif result.message:
self._last_observation = result.message
# Add assistant response to context
self._context.append(
MessageBuilder.create_assistant_message(
f"<think>{response.thinking}</think><answer>{response.action}</answer>"
)
)
# Check if finished
finished = action.get("_metadata") == "finish" or result.should_finish
if finished and self.agent_config.verbose:
msgs = get_messages(self.agent_config.lang)
print("\n" + "🎉 " + "=" * 48)
print(
f"✅ {msgs['task_completed']}: {result.message or action.get('message', msgs['done'])}"
)
print("=" * 50 + "\n")
return StepResult(
success=result.success,
finished=finished,
action=action,
thinking=response.thinking,
message=result.message or action.get("message"),
)
@property
def context(self) -> list[dict[str, Any]]:
"""Get the current conversation context."""
return self._context.copy()
@property
def step_count(self) -> int:
"""Get the current step count."""
return self._step_count
